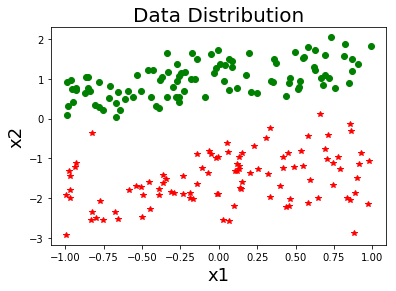
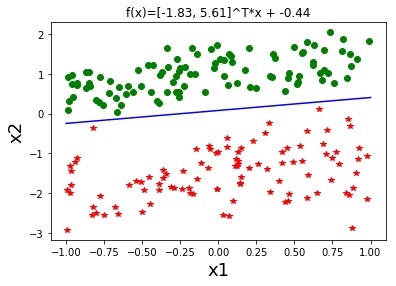
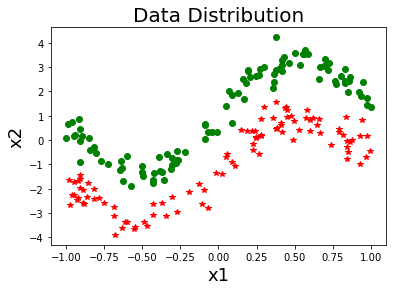
class cSVM:
def __init__(self):
self.epsilon = 0.001
self.bopt = None
self.sv = None
self.sy = None
self.salpha = None
self.kernel = None
def train(self, x, y, C=1, a0=None,
options={'ftol': 1e-9, 'disp': True}):
assert (x.shape[1] == y.shape[1]) and (y.shape[0] == 1)
N = x.shape[1]
if a0 is None:
a0 = np.random.normal(0, 1, N)
# parameter bounds: 0 <= alpha_i <= C for all i's
bounds = optimize.Bounds([0 for i in range(N)],
[C for i in range(N)])
# inequality constraints: dummy
ineq_cons = {'type': 'ineq',
'fun' : lambda a: np.array([0]), # (1,)
'jac' : lambda a: np.zeros((1,N))} # (M,N)
# equality constraint: sum_i y_i alpha_i = 0
eq_cons = {'type': 'eq', 'fun' : lambda a: np.dot(y,
a.reshape((-1, 1))).reshape((-1,)),
'jac' : lambda a: y.reshape((1,N))}
# Objective
K = self.kernel(x, x) # N x N
H = np.dot(y.T, y) * K # N x N
def dual_minf(a, H): # dual loss in minimization form
a = a.reshape((-1,1))
Q = 0.5 * np.dot(a.T, np.dot(H, a)) - np.sum(a)
return np.asscalar(Q)
def dual_grad(a, H, N): # gradient of dual loss
dQ = np.dot(H, a.reshape((-1,1))) - np.ones((N,1))
return dQ.reshape((-1,)) # (N,)
minf = lambda a: dual_minf(a, H)
gradf = lambda a: dual_grad(a, H, N)
res = optimize.minimize(minf, a0, method='SLSQP',
jac=gradf, constraints=[ineq_cons, eq_cons],
bounds=bounds, options=options)
if not res.success:
return res
alpha = res.x.reshape((-1,1))
sv_ids = np.where(alpha > self.epsilon)[0]
svp_ids = np.where( np.logical_and(alpha > self.epsilon,
alpha < C - self.epsilon) )[0]
Ns = len(sv_ids)
Np = len(svp_ids)
if Np == 0: # No support vector on the edge
print('# No support vector on the edge.')
svp_ids = sv_ids
Np = Ns
# support vectors
self.sv = x[:, sv_ids] # D x Ns
self.sy = y[0, sv_ids].reshape((1,-1)) # 1 x Ns
spy = y[0, svp_ids].reshape((1,-1)) # 1 x Np
# support alphas
self.salpha = alpha[sv_ids]
# optimal b
sK = K[np.repeat(sv_ids, Np),
np.tile(svp_ids, Ns)].reshape((Ns, Np))
self.bopt = np.mean(spy - \
np.dot(self.salpha.T * self.sy, sK))
return res
def decision_score(self, x):
assert x.shape[0] == self.sv.shape[0] # x in D x N
# Compute support kernels
sK = self.kernel(x, self.sv) # N x Ns
assert (sK.shape[0] == x.shape[1])
and (sK.shape[1] == self.sv.shape[1])
yhat = np.dot(sK, self.salpha*self.sy.reshape((-1,1))) \
+ self.bopt
return yhat.T # 1 x N