3 การเรียนรู้ของเครื่องและโครงข่ายประสาทเทียม
“If I have seen further, it is by standing upon the shoulders of giants.”
—Isaac Newton
“ถ้าผมมองเห็นได้ไกลกว่า มันก็มาจากการยืนอยู่บนไหลของเหล่ายักษ์”
—ไอแซค นิวตัน
วิธีการเรียนรู้ของเครื่อง มีมากมาย หลากหลายแบบ แตกต่างกันไปตามลักษณะงานที่ต้องการ. ตัวอย่าง การปรับเส้นโค้งด้วยฟังก์ชันพหุนาม ในหัวข้อ 1.1 อภิปรายตัวอย่างง่าย ๆ ที่เป็นแนวทางหลัก และสะท้อนหลักการที่สำคัญของการเรียนรู้ของเครื่อง. หัวข้อ 1.2 อภิปรายพื้นฐาน หลักการ และประเด็นสำคัญของศาสตร์การเรียนรู้ของเครื่อง. หัวข้อ 1.3 อภิปรายโครงข่ายประสาทเทียม ซึ่งเป็นแบบจำลองที่สำคัญ ใช้งานได้กว้างขวาง และเป็นหนึ่งในศาสตร์และศิลป์ของการเรียนรู้ของเครื่อง. หัวข้อ 1.4 อภิปรายการประยุกต์ใช้งานของโครงข่ายประสาทเทียม. หัวข้อ 1.5 อภิปรายคำแนะนำทั้งสำหรับการใช้งานโครงข่ายประสาทเทียม และการใช้งานการเรียนรู้ของเครื่องโดยทั่วไป.
3.1 การปรับเส้นโค้งด้วยฟังก์ชันพหุนาม
การทำแบบจำลอง คือการสร้างสมการคณิตศาสตร์ เพื่อคำนวณค่าคำตอบ \(\boldsymbol{y}\) จากค่าคำถาม \(\boldsymbol{x}\). และหลังจากทำแบบจำลองเสร็จเรียบร้อยแล้ว แบบจำลองที่ได้ (สมการคณิตศาสตร์ที่นิยามการคำนวณครบทุกอย่างทุกขั้นตอน) จะสามารถนำไปใช้อนุมานหรือทำนายค่าคำตอบ สำหรับคำถามที่สงสัยได้.
พิจารณากรณีที่ทั้งอินพุตและเอาต์พุตเป็นมิติเดียว นั่นคือ คำถาม \(x \in \mathbb{R}\) และ \(y \in \mathbb{R}\). หากต้องการจะทำนายค่า \(y\) ที่สัมพันธ์กับค่า \(x\) โดยที่มีตัวอย่างข้อมูลเป็นคู่ ๆ ของ \((x,y)\) ได้แก่ \((x_1, y_1)\), \((x_2, y_2)\), \(\ldots\), \((x_n, y_n)\) ทั้งหมดจำนวน \(n\) คู่. ตัวแปรต้น \(x\) เป็นค่าที่ถามมา เพื่อหา \(y\) ที่เป็นตัวแปรตาม หรือค่าที่อยากได้คำตอบไป. แต่ละคู่ \((x_i, y_i)\) อาจเรียกว่า จุดข้อมูล (datapoint).
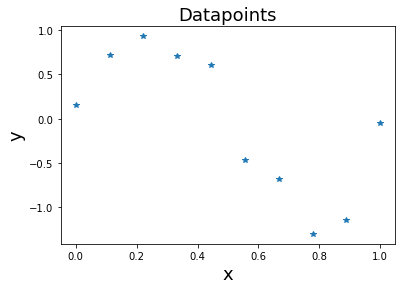
รูป 1.1 แสดงตัวอย่างจุดข้อมูล \(10\) จุด. ตำแหน่งของแต่ละจุดข้อมูลในภาพ ระบุจากค่า \(x\) ตามแกนนอน และค่า \(y\) ตามแกนตั้ง. ตัวแปรต้น \(x\) อาจเรียก อินพุต หรือข้อมูลนำเข้า (input) และตัวแปรตาม \(y\) อาจเรียก เอาต์พุต หรือข้อมูลนำออก (output). จากตัวอย่างในภาพ จุดข้อมูลแรกสุด มีค่า \(x = 0\) ค่า \(y = 0.16\).
เป้าหมายของตัวอย่างนี้คือ การทำนายค่าประมาณเอาท์พุต \(y\) ของค่าอินพุต \(x\) ที่สงสัย โดยอินพุต \(x\) อาจจะเป็นค่าเดิม หรืออาจจะเป็นค่าใหม่ที่ไม่เคยเห็นมาก่อน. แนวทางคือ การใช้แบบจำลอง ซึ่งเป็นการคำนวณทางคณิตศาสตร์ ที่เป็นฟังก์ชันของตัวแปร \(x\) และใช้ค่าที่ฟังก์ชันคำนวณได้ ทายเป็นค่า \(y\). แบบจำลองที่จะเลือกใช้สำหรับตัวอย่างนี้ คือ ฟังก์ชันพหุนาม (polynomial function). ฟังก์ชันพหุนาม \(f\) คำนวณค่า \(y\) จาก \(x\) โดย \[\begin{eqnarray} y &=& f(x, \boldsymbol{w}) = w_0 + w_1 \cdot x + w_2 \cdot x^2 + w_3 \cdot x^3 + \ldots + w_m \cdot x^m \label{eq: polynomial} \end{eqnarray}\] เมื่อ \(\boldsymbol{w} = [w_0, \; w_1 \; w_2, \; \ldots, w_m]^T\) เป็นค่าพารามิเตอร์ของฟังก์ชันพหุนาม และ \(m\) เป็นระดับขั้น (degree) ของฟังก์ชันพหุนาม. ก่อนที่จะสามารถนำฟังก์ชันพหุนาม ไปใช้ทำนายค่า \(y\) จากค่า \(x\) ที่ถามได้ ต้องกำหนดระดับขั้น \(m\) และค่าของพารามิเตอร์ \(\boldsymbol{w}\) ให้เรียบร้อยก่อน.
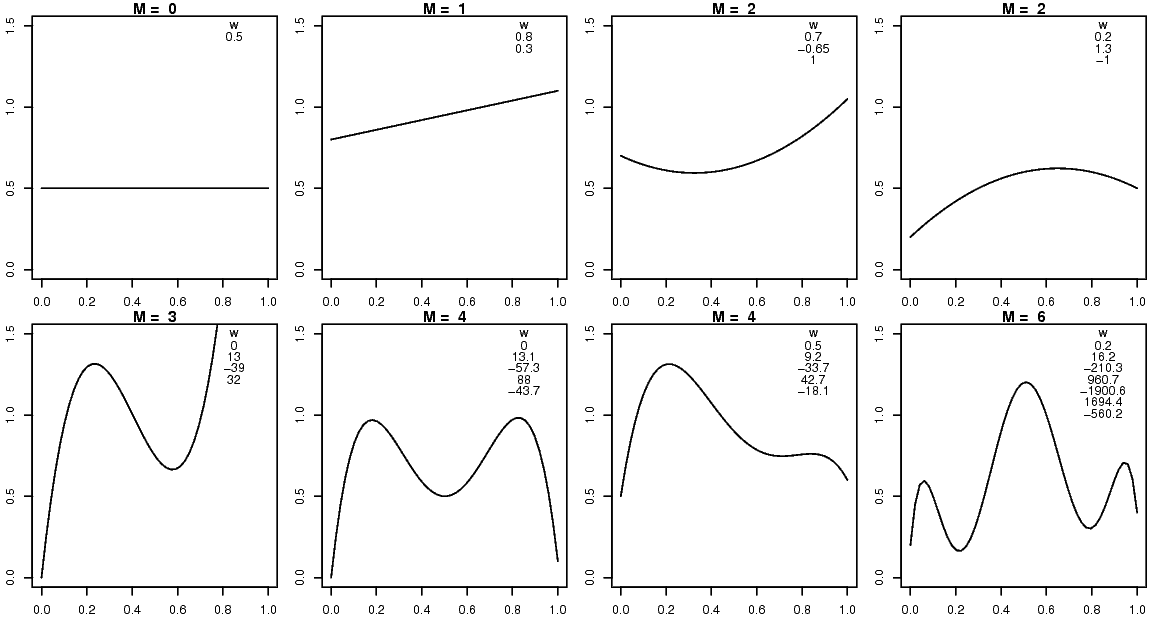
ตัวอย่างเช่น หากเลือก ระดับขั้น \(m = 2\) และค่าของพารามิเตอร์ \(\boldsymbol{w} = [0.7, -0.65, 1]^T\) สำหรับแบบจำลอง \(f_1\) นั่นคือ ฟังก์ชันพหุนาม \(y = f_1(x) = 0.7 -0.65 x + x^2\) แล้วที่ \(x = 0.5\) จะทำนายค่า \(y\) เป็น \(0.625\). ระดับขั้น และค่าของพารามิเตอร์ที่เลือกใช้ ส่งผลโดยตรงกับค่าที่ทำนาย เช่น หากเลือก ระดับขั้น \(m = 3\) และค่าของพารามิเตอร์ \(\boldsymbol{w} = [0, 13, -39, 32]^T\) สำหรับแบบจำลอง \(f_2\) นั่นคือ ฟังก์ชันพหุนาม \(y = f_2(x) = 13 x -39 x^2 + 32 x^3\) แล้วที่ \(x = 0.5\) จะทำนายค่า \(y\) เป็น \(0.75\) ซึ่งแตกต่างจากผลทำนายจาก \(f_1\).
ระดับขั้นและค่าพารามิเตอร์ต่าง ๆ จะให้ผลการทำนายต่างกัน. รูป 1.2 แสดงพฤติกรรมการทำนาย ของฟังก์ชันพหุนาม เมื่อเลือกใช้ระดับขั้นและค่าพารามิเตอร์ต่าง ๆ. พฤติกรรมการทำนาย หมายถึง ความสัมพันธ์ระหว่างอินพุตกับเอาต์พุต. การปรับเส้นโค้ง ใช้ประโยชน์จากการที่ พฤติกรรมการทำนายเปลี่ยนตามระดับขั้นและค่าพารามิเตอร์. ดังนั้น การปรับเส้นโค้ง ทำได้โดยปรับระดับขั้น และค่าพารามิเตอร์ของสมการ เพื่อปรับเส้นโค้งให้ได้ผลการทำนายที่ดีขึ้น.
ระดับขั้นของสมการพหุุนาม จะกำหนดจำนวนพารามิเตอร์ของฟังก์ชันพหุนาม. การเลือกระดับขั้น เป็นการเลือกความสามารถของแบบจำลองโดยรวม. ระดับขั้นสูง แบบจำลองจะมีความสามารถมาก แต่ก็เพิ่มจำนวนพารามิเตอร์ที่ต้องหาค่า เท่ากับ เพิ่มความยากในการปรับแบบจำลองขึ้น. หัวข้อ 1.2 อภิปรายวิธีการเลือกระดับขั้น. ตอนนี้ สมมติว่าระดับขั้น \(m\) ถูกเลือกมาแล้ว หากเลือกระดับขั้นเป็น \(m\) ฟังก์ชันพหุนามจะมีจำนวนพารามิเตอร์ เป็น \(m+1\) ตัว. การหาค่าของพารามิเตอร์เหล่านี้ จะเรียกว่า การฝึก (training) หรือ การเรียนรู้ (learning).
3.1.0.0.1 การฝึกแบบจำลอง.
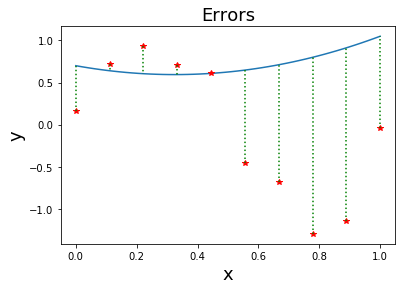
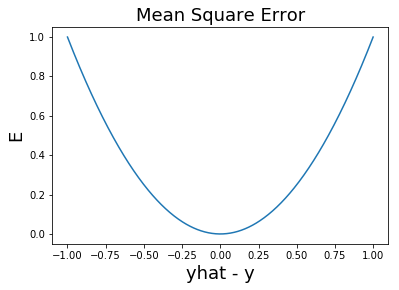
การฝึกแบบจำลอง คือการหาค่าพารามิเตอร์ของแบบจำลอง เพื่อให้แบบจำลองทำนายได้ถูกต้องมากที่สุด หรือกล่าวอีกอย่างคือ เพื่อให้แบบจำลองทำนายผิดน้อยที่สุด. การวัดว่าแบบจำลองทำนายได้ผิดมากน้อยเท่าใด สามารถใช้แนวทางของวิธีกำลังสองน้อยที่สุด (Least Square method) ได้. วิธีกำลังสองน้อยที่สุด วัดว่าแบบจำลองทำนายได้ผิดมากน้อยเท่าใด จาก ผลต่างกำลังสอง ระหว่างค่าเอาต์พุตที่ทำนายกับค่าเอาต์พุตจริง. นั่นคือ \(E_n = (\hat{y}_n - y_n)^2\) เมื่อ \(E_n\) คือความผิดพลาด (error) ของการทำนายจุดข้อมูลที่ \(n^{th}\) ซึ่งวัดจากผลต่างกำลังสองระหว่าง ค่าเอาต์พุตที่ทำนาย \(\hat{y}_n\) สำหรับจุดข้อมูลที่ \(n^{th}\) และค่าเอาต์พุตจริง \(y_n\) ของจุดข้อมูลที่ \(n^{th}\). ค่า \(y_n\) ที่ได้จากข้อมูล อาจเรียกว่า เอาต์พุตจริง (ground truth) หรือ ค่าเฉลย. รูป 1.3 แสดงผลต่างระหว่างค่าที่ทำนายและค่าเอาต์พุตจริง. ความผิดพลาดรวม สามารถคำนวณได้ดังสมการ \(\eqref{eq: SSE}\). \[\begin{eqnarray} E &=& \frac{1}{2} \sum_{n=1}^N E_n = \frac{1}{2} \sum_{n=1}^N (\hat{y}_n - y_n)^2 \label{eq: SSE} . \end{eqnarray}\] การยกกำลังสอง ช่วยให้ความผิดพลาดจากการทายขาดไม่ไปหักล้างกับความผิดพลาดจากการทายเกิน. ค่าคงที่ \(\frac{1}{2}\) ถูกใช้เพื่อความสะดวก (ที่จะได้เห็นต่อไป เมื่อทำการหาอนุพันธ์).
ด้วยวิธีวัดความผิดพลาดนี้ การฝึกฟังก์ชันพหุนามระดับขั้น \(m\) ก็สามารถทำได้โดย \(\boldsymbol{w}^\ast = \arg\min_{\boldsymbol{w}} E\). เมื่อจบการฝึกแล้ว ค่าพารามิเตอร์ \(\boldsymbol{w}^\ast\) จะถูกนำไปใช้กับฟังก์ชันพหุนามเพื่อทำนาย. ฟังก์ชันพร้อมด้วยค่าพารามิเตอร์ที่ได้จากการฝึก มักจะเรียกรวม ๆ ว่า แบบจำลองที่ฝึกแล้ว.
3.1.0.0.2 ตัวอย่างการฝึกแบบจำลองพหุนามระดับขั้นหนึ่ง.
สำหรับตัวอย่างข้อมูลในรูป 1.1 สมมติระดับขั้นที่เลือกคือ ระดับขั้นหนึ่ง (\(m=1\)) นั่นคือ \(\hat{y} = w_0 + w_1 x\). ในการฝึกแบบจำลอง ซึ่งคือการหา \(w_0\) และ \(w_1\) ที่ทำนายผิดพลาดน้อยที่สุด นั่นคือ การหา \(w_0^\ast, w_1^\ast = \arg\min_{w_0, w_1} E\) เมื่อ \(E = \frac{1}{2} \sum_{n=1}^N E_n\) และ \(E_n = (w_0 + w_1 x_n - y_n)^2\).
ค่าความผิดพลาดต่ำสุด เกิดเมื่อ \(\frac{\partial E}{\partial w_0} = 0\) และ \(\frac{\partial E}{\partial w_1} = 0\) ซึ่งเมื่อเขียน \(E\) ในรูปฟังก์ชันของ \(w_0\) และ \(w_1\) จะได้ \[\begin{eqnarray} \frac{\partial \frac{1}{2} \sum_{n=1}^N \{ w_0 + w_1 x_n - y_n \}^2}{\partial w_0} &=& 0, \label{eq: polynomial derivatives 2a} \\ \frac{\partial \frac{1}{2} \sum_{n=1}^N \{ w_0 + w_1 x_n - y_n \}^2}{\partial w_1} &=& 0 \label{eq: polynomial derivatives 2b} \end{eqnarray}\] และหลังจากหาอนุพันธ์เสร็จจะได้ \[\begin{eqnarray} \sum_{n=1}^N \{ (w_0 + w_1 x_n - y_n) \cdot (1 + 0 - 0) \} &=& 0, \label{eq: polynomial derivatives 3a} \\ \sum_{n=1}^N \{ (w_0 + w_1 x_n - y_n) \cdot (0 + x_n - 0) \} &=& 0. \label{eq: polynomial derivatives 3b} \end{eqnarray}\]
ทำการจัดรูปใหม่ โดยเรียงตามพารามิเตอร์ จะได้ \[\begin{eqnarray} w_0 \sum_{n=1}^N \{ 1 \} + w_1 \sum_{n=1}^N \{ x_n \} - \sum_{n=1}^N \{ y_n \} &=& 0, \label{eq: poly 4a} \\ w_0 \sum_{n=1}^N \{ x_n \} + w_1 \sum_{n=1}^N \{ x_n^2 \} - \sum_{n=1}^N \{ y_n \cdot x_n \} &=& 0 \label{eq: poly 4b} \end{eqnarray}\] ซึ่งเมื่อจัดรูปสมการ \(\eqref{eq: poly 4a}\) และ \(\eqref{eq: poly 4b}\) ให้อยู่ในรูปเมทริกซ์จะได้ \[\begin{eqnarray} \left[ \begin{matrix} N & \sum_{n=1}^N x_n \\ \sum_{n=1}^N x_n & \sum_{n=1}^N x_n^2 \end{matrix} \right] \cdot \left[ \begin{matrix} w_0 \\ w_1 \end{matrix} \right] = \left[ \begin{matrix} \sum_{n=1}^N y_n \\ \sum_{n=1}^N y_n \cdot x_n \end{matrix} \right]. \label{eq: polynomial M1} \end{eqnarray}\]
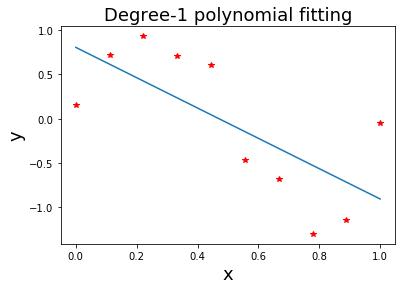
เมื่อนำค่าจุดข้อมูลในรูป 1.1 มาคำนวณ ผลจะได้ว่า \(N = 10\), \(\sum_{n=1}^N x_n = 5\), \(\sum_{n=1}^N x_n^2 = 3.519\), \(\sum_{n=1}^N y_n = -0.498\), และ \(\sum_{n=1}^N y_n x_n = -1.992\). เมื่อแก้สมการแล้วจะได้ค่า \([w_0, \; w_1]^T\) \(= [0.805, \; -1.710]^T\). นั่นคือ แบบจำลอง \(\hat{y} = 0.805 - 1.71 x\) พฤติกรรมของแบบจำลองนี้แสดงดังในรูป 1.4.
การใช้งาน หรือการทำนายด้วยแบบจำลอง \(\hat{y} = 0.805 - 1.71 x\) คือ การคำนวณโดยแทนค่า \(x\) ที่ถามลงไป เช่น ที่ \(x = 0.5\) แบบจำลองนี้ทำนาย \(\hat{y} = 0.805 - 1.71 (0.5)\) \(=-0.05\). ความสามารถของแบบจำลองนี้ ประเมินคราว ๆ ได้จากค่าความผิดพลาดรวม (สมการ \(\eqref{eq: SSE}\)) \(E = 1.487\).
3.1.0.0.3 เกร็ดความรู้สมองมนุษย์
(เรียบเรียงจาก และ )
โดยเฉลี่ยแล้ว สมองมนุษย์มีขนาดประมาณ \(1.13\) ถึง \(1.26\) ลิตร และหนักประมาณ \(1.3\) กก. ใช้ออกซิเจนประมาณ \(20\) เปอร์เซ็นของปริมาณทั้งหมดที่ร่างกายรับเข้าไป และใช้กำลังงานประมาณ \(25\) วัตต์.
สมองเชื่อมต่อกับส่วนอื่น ๆ ของร่างกายผ่านไขสันหลัง และระบบประสาทนอกส่วนกลาง (Peripheral Nervous System คำย่อ PNS) ไขสันหลังทำหน้าที่หลัก ๆ คือเชื่อมต่อสัญญาณควบคุมจากสมองไปยังส่วนต่าง ๆ ของร่างกาย และส่งผ่านสัญญาณรับรู้จากส่วนต่าง ๆ ของร่างกายกลับไปยังสมอง และไขสันหลังเองก็มีระบบประสาทของตัวเองที่ช่วยทำงาน เช่น การควบคุมการตอบสนองฉับพลัน. ระบบประสาทนอกส่วนกลาง มีหน้าที่หลัก คือเชื่อมต่อสัญญาณจากสมองและไขสันหลังไปสู่อวัยวะต่าง ๆ.
การทำงานของสมองมีลักษณะคล้ายคณะกรรมการของกลุ่มผู้เชี่ยวชาญจำนวนมาก นั่นคือ ส่วนต่าง ๆ ของสมองทำงานร่วมกัน แต่ว่าแต่ละส่วนของสมองมีหน้าที่เฉพาะด้าน. เราอาจมองได้ว่าส่วนของสมองมีสามส่วนใหญ่ ๆ คือ สมองส่วนบน (forebrain), สมองส่วนกลาง (midbrain), และ สมองส่วนล่าง (hindbrain).
สมองส่วนล่างนับรวมส่วนบนของไขสันหลัง ก้านสมอง (brain stem) และ เซเรเบลัม (cerebellum). สมองส่วนล่างจะควบคุมการทำงานที่เป็นพื้นฐานของการดำรงชีพ เช่น การหายใจ และการเต้นของหัวใจ. เซเรเบลัมช่วยประสานงานเรื่องการเคลื่อนไหวและการเรียนรู้ของการเคลื่อนไหวที่เกิดจากการฝึกทำซ้ำ ๆ เช่น การเล่นเปียโนหรือการตีลูกเทนนิส จะอาศัยการทำงานของเซเรเบลัมช่วย.
สมองส่วนกลางอยู่ด้านบนของก้านสมอง ทำหน้าที่เกี่ยวกับการควบคุมการตอบสนองแบบฉับพลัน และเป็นส่วนหนึ่งในระบบการควบคุมการเคลื่อนไหวของดวงตาและการเคลื่อนไหวโดยสมัครใจอื่น ๆ. สมองส่วนกลางนี้มีส่วนที่ทำงานประมวลผลภาพอยู่ด้วย. สภาวะเห็นทั้งบอด (blindsight) เป็นสภาวะของผู้พิการทางสายตา ที่การพิการเกิดจากส่วนประมวลผลภาพหลักที่เปลือกสมองส่วนการเห็น (visual cortex ซึ่งจัดอยู่ในสมองส่วนบน)ไม่สามารถทำหน้าที่ได้ แต่ดวงตาและส่วนอื่น ๆ ในระบบการมองเห็น รวมถึงส่วนประมวลผลภาพของสมองส่วนกลางยังดีอยู่. สภาวะเช่นนี้ ตัวผู้พิการจะไม่รับรู้ถึงการมองเห็น แต่เมื่อมีการทดลอง โดยบังคับให้ผู้มีสภาวะเห็นทั้งบอดบรรยายรูปร่างหรือตำแหน่งของวัตถุด้วยการเดา ผู้มีสภาวะเห็นทั้งบอดจะบรรยายได้ถูกต้องทั้งรูปร่าง ตำแหน่ง และการเคลื่อนไหว ซึ่งความถูกต้องแม่นยำที่ได้สูงมากเกินกว่าที่จะได้มาจากการคาดเดา. คำอธิบายสภาวะนี้ก็คือ สมองกลับไปใช้ผลการประมวลภาพจากสมองส่วนกลาง ซึ่งแม้จะไม่มีความสามารถในการประมวลผลได้ดีเท่ากับเปลือกสมองส่วนการเห็น แต่ก็ช่วยให้เกิดการมองเห็นใต้จิตสำนึกนี้เกิดขึ้นได้.
เนื่องจากระบบประมวลผลภาพในสมองมีทั้งที่สมองส่วนกลางและบริเวณเปลือกสมองส่วนการเห็นในสมองส่วนบน ทฤษฎีวิวัฒนาการเชื่อว่า การประมวลภาพที่สมองส่วนกลางเป็นวิวัฒนาการในช่วงก่อน (สัตว์หลายชนิด เช่น กบ ใช้การประมวลภาพที่สมองส่วนกลางเป็นหลัก) และเปลือกสมองส่วนการเห็นเป็นวิวัฒนาการในช่วงต่อมา. ผู้เชี่ยวชาญด้านประสาทวิทยาเดวิด ลินเดน (ผู้เขียนหนังสือ Accidental Mind) ได้อธิบายเพิ่มเติมในการสนทนาส่วนตัวว่า หากการประมวลผลภาพของสมองส่วนกลางเสียหาย แต่ส่วนอื่น ๆ ในระบบการมองเห็นยังดีอยู่ รวมถึงเปลือกสมองส่วนการเห็นก็ยังดีอยู่ ผู้ป่วยจะรับรู้ถึงการมองเห็นได้ แต่พบว่าผู้ป่วยจะมีการตอบสนองการประสานงานระหว่างมือและตา (hand-eye coordination) ที่ช้าลงอย่างชัดเจน.
สมองส่วนบนเป็นส่วนที่ใหญ่ที่สุดในสามส่วน. สมองส่วนบนประกอบด้วยเซเรบรัม (cerebrum) และส่วนสมองใน (the inner brain). หมายเหตุ เซเรบรัม (ของสมองส่วนบน) มาจากภาษาลาติน แปลตรงตัวว่า สมอง ขณะที่ เซเรเบลัม (ของสมองส่วนล่าง) มาจากภาษาลาติน ซึ่งแปลตรงตัวว่า สมองน้อย. เซเรบรัมคือภาพของสมองที่คนทั่วไปจะนึกถึงเมื่อกล่าวถึงสมอง. เซเรบรัม ทำหน้าที่หลักในการรับรู้ ความจำ การวางแผน การคิด การจินตนาการ รวมถึงศีลธรรม นิสัย และบุคคลิกภาพ. เมื่อมองจากด้านบน เซเรบรัมดูเหมือนจะแบ่งได้เป็นซีกซ้ายและซีกขวา โดยมีดูเหมือนมีร่องแบ่งสมองสองซีกนี้ออกจากกัน. สมองทั้งสองซีกเชื่อมต่อกันผ่านเส้นใยประสาทเรียกว่า คอร์ปัส คาโลซัม (corpus callosum). สมองทั้งสองซีกนี้ทำงานร่วมกัน แต่สมองซีกซ้ายจะควบคุมการทำงานของร่างกายซีกขวา และสมองซีกขวาจะควบคุมการทำงานของร่างกายซีกซ้าย โดยสมองซีกซ้ายจะเด่นด้านการทำงานเกี่ยวกับภาษา การวิเคราะห์รายละเอียด และทักษะเชิงรูปธรรม ในขณะที่สมองซีกขวาจะเด่นด้านการอ่านภาพรวม และทักษะเชิงนามธรรม. การทำงานไขว้ระหว่างซีกสมองกับร่างกายนั้น แม้จะยังไม่มีคำอธิบายว่าเหตุใดกลไกของร่างกายจึงเป็นเช่นนั้น แต่ข้อเท็จจริงคือสัญญาณจากสมองซีกหนึ่งจะไขว้ไปบังคับร่างกายอีกซีกหนึ่ง ดังนั้น หากสมองซีกหนึ่งเสียหาย ร่ายกายอีกซีกหนึ่งจะได้รับผลกระทบ เช่น ผู้ป่วยโรคหลอดเลือดสมอง เมื่อเกิดสมองซีกขวาเสียหาย จะส่งผลให้ผู้ป่วยเป็นอัมพาตในซีกซ้ายของร่างกาย.
การศึกษาที่น่าสนใจเกี่ยวกับสมองซีกซ้ายและขวา หลายกรณีได้มาจากการศึกษาผู้ป่วยโรคลมชักรุนแรง ที่แพทย์ต้องตัดคอร์ปัส คาโลซัมเพื่อลดความรุนแรงของอาการลมชักไม่ให้แพร่ขยายข้ามซีกสมองได้. หนึ่งในตัวอย่าง คือ การศึกษาที่นำผู้ป่วยที่ผ่านการตัดการเชื่อมต่อระหว่างสมองซีกซ้ายและขวาออกจากกัน มาใส่คอนแทกเลนส์พิเศษเพื่อแยกการมองเห็นระหว่างตาซ้ายและตาขวาออกจากกัน. ตาซ้ายและร่างการซีกซ้ายเชื่อมโยงกับสมองซีกขวา ตาขวาและร่างการซีกขวาเชื่อมโยงกับสมองซีกซ้าย. เมื่อให้ตาขวารับภาพของเท้าของไก่ และให้ตาซ้ายรับภาพของบ้านที่ถูกหิมะท่วม พร้อมสั่งให้ผู้ทดลองชี้เลือกภาพที่เกี่ยวข้องด้วยมือซ้ายและขวา ผู้ทดลองชี้มือขวาไปที่ภาพตัวแม่ไก่ และชี้มือซ้ายไปที่ภาพพลั่ว ผู้ทดลอง อธิบายถึงเท้าไก่ได้ แต่ไม่สามารถอธิบายภาพของบ้านที่ถูกหิมะท่วมได้ และเมื่อให้ผู้ทดลองอธิบายเหตุผลที่ชี้เลือกภาพแม่ไก่ และพลั่ว สมองส่วนซ้าย ซึ่งไม่ได้รับรู้ภาพของบ้านที่ถูกหิมะท่วม ก็พยายามอธิบายไปว่า เท้าไก่เกี่ยวข้องกับแม่ไก่ และพลั่วเกี่ยวข้องคือเป็นเครื่องมือตักมูลไก่. กรณีนี้ ผู้เชี่ยวชาญอธิบายว่า สมองซีกซ้ายซึ่งมีความสามารถทางภาษา แต่ไม่ได้รับภาพที่สมองซีกขวาเห็น ไม่ได้รับรู้ถึงภาพบ้านหิมะท่วม แต่สมองซีกขวา แม้จะรับรู้ภาพของบ้านหิมะท่วมและยังบังคับมือซ้ายไปชี้ที่พลั่ว ซึ่งเป็นสิ่งที่มักจะเชื่อมโยงกับภาพหิมะท่วม ในกลุ่มคนที่คุ้นเคยกับสภาพหิมะ แต่สมองซีกขวาไม่มีความสามารถทางภาษา จึงไม่สามารถอธิบายออกมาเป็นคำพูดได้.
เซเรบรัมแต่ละซีกยังสามารถแบ่งเป็นส่วนย่อย ๆ ลงไปได้อีก ซึ่งแต่ละส่วนของเซเรบรัมมักจะเรียกว่ากลีบ(lobe). เซเรบรัมมีกลีบหลัก ๆ เช่น กลีบหน้า (frontal lobe), กลีบข้าง (parietal lobe), กลีบท้ายทอย (occipital lobe), และกลีบขมับ (temporal lobe). สมองกลีบหน้าจะอยู่บริเวณหลังหน้าผากของเรา และทำหน้าที่เกี่ยวกับ การวางแผน การจินตนาการถึงอนาคต การใช้เหตุผล การควบคุมตัวเอง บุคคลิกภาพ และ ศีลธรรม. ลึกเข้าไปท้าย ๆ กลีบจะเป็นบริเวณที่ทำหน้าที่เกี่ยวกับการควบคุมการเคลื่อนไหว. ในกลีบหน้าของสมองซีกซ้ายจะมีบริเวณโบรก้า (ฺBroca’s area) ซึ่งเป็นส่วนที่ทำหน้าที่เกี่ยวกับการใช้ภาษา.
สมองกลีบข้างซึ่งอยู่ถัดจากกลีบหน้าเข้ามา (บริเวณใต้กลางกระหม่อม) ทำหน้าที่เกี่ยวกับรส กลิ่น สัมผัส รวมถึงการรับรู้การเคลื่อนไหวของร่างกาย ความสามารถในการอ่านหนังสือและการคิดคำนวณตัวเลข ก็เกี่ยวข้องกับสมองกลีบข้าง. สมองกลีบท้ายทอยอยู่ถัดจากกลีบข้างไปทางหน้าหลัง (บริเวณท้ายทอย) ทำหน้าที่หลักเกี่ยวกับการมองเห็น. เปลือกสมองส่วนการเห็น ซึ่งเป็นส่วนประมวลผลการมองเห็นหลักก็อยู่ในบริเวณกลีบท้ายทอย. สมองกลีบขมับจะอยู่ใต้กลีบหน้าและกลีบข้าง ซึ่งเมื่อเทียบกับภายนอกแล้วจะอยู่บริเวณขมับ. สมองกลีบขมับทำหน้าที่หลักเกี่ยวกับการประมวลผลเสียงต่าง ๆ และมีหน้าที่ช่วยในการรวมความจำและความรับรู้ต่าง ๆ ทั้งภาพ เสียง กลิ่น และ สัมผัส เข้าด้วยกัน.
ที่ผิวชั้นนอกของเซเรบรัมจะเป็นชั้นของเนื้อเยื่อที่หนาประมาณ \(2\) ถึง \(4\) มิลลิเมตร ซึ่งเรียกว่า เซเรบรอลคอร์เท็กซ์ (cerebral cortex). การประมวลผลของสมองส่วนใหญ่เชื่อกันว่าเกิดขึ้นภายในเนื้อเยื่อส่วนนี้ เนื้อเยื่อส่วนนี้จะมีสีเข้มกว่าเนื้อเยื้อส่วนด้านใน และมักถูกอ้างถึงในชื่อของเนื้อเทา (gray matter) เปรียบเทียบกับเนื้อขาว (white matter) ซึ่งอยู่ภายใน. เนื้อเทาจะประกอบด้วยเซลล์ประสาท หลอดเลือดฝอย และ เซลล์เกลีย. เซลล์ประสาทในเนื้อเทาจะมีไขมันที่เป็นฉนวนน้อยกว่าเซลล์ประสาทในเนื้อขาว จึงทำให้สีของเนื้อเยื้อโดยรวมดูเข้มกว่า. (ดูรายละเอียดของเซลล์ประสาท ในเกร็ดความรู้เซลล์ประสาท.) เนื่องจากเซเรบรอลคอร์เท็กซ์เป็นผิวของสมอง รอยหยักของสมองจะช่วยเพิ่มพื้นที่ผิวและปริมาณของเนื้อเทาซึ่งสัมพันธ์กับปริมาณของข้อมูลที่สมองสามารถประมวลผลได้.
ส่วนสมองในเป็นอีกบริเวณในสมองส่วนบน. ส่วนสมองในนี้จะเชื่อมต่อไขสันหลังเข้ากับเซเรบรัม. ส่วนสมองในทำหน้าที่เกี่ยวอารมณ์ มีส่วนในการเปลี่ยนแปลงการรับรู้และการตอบสนองไปตามสถานะของอารมณ์ในขณะนั้น ๆ มีส่วนช่วยเริ่มการเคลื่อนไหวต่าง ๆ ที่เราทำโดยเราไม่ต้องคิดถึงการเคลื่อนไหวเหล่านั้น และมีส่วนสำคัญในกระบวนการสร้างความจำ. ส่วนประกอบต่าง ๆ ของส่วนสมองในนี้จะมีเป็นคู่ ๆ ทางซ้ายและขวา โดยมีส่วนประกอบที่สำคัญ เช่น ไฮโปธาลามัส (hypothalamus) ธารามัส (thalamus) บาซอลแกงเกลีย (basal ganglia) อะมิกดาลา (amygdala) และฮิปโปแคมปัส (hippocampus). ไฮโปธาลามัสเป็นเสมือนศูนย์กลางการจัดการอารมณ์. ธาลามัสช่วยจัดการข้อมูลที่ผ่านไปมาระหว่างเซเรบรัมและไขสันหลัง. บาซอลแกงเกลียช่วยการเริ่มและประสานงานการเคลื่อนไหวต่าง ๆ. โรคพาร์กินสันซึ่งผู้ป่วยจะมีอาการที่เด่นชัดคือมีปัญหากับการเคลื่อนไหว เช่น อาการสั่น เดินหรือเคลื่อนไหวได้ช้า เป็นโรคที่เกี่ยวพันกับเซลล์ประสาทที่เชื่อมต่อกับบาซอลแกงเกลียนี้. อะมิกดาลาทำหน้าที่เกี่ยวกับอารมณ์ ความกลัว ความก้าวร้าว และ ความจำที่เกี่ยวข้องกับอารมณ์ความรู้สึก. มีงานศึกษาที่พบความเกี่ยวข้องกันระหว่างขนาดของอะมิกดาลาของบุคคลกับความสัมพันธ์ทางสังคมของบุคคลนั้น. ฮิปโปแคมปัสทำหน้าที่จัดส่งความจำใหม่ไปเก็บในตำแหน่งที่เหมาะสมในเซเรบรัม และค้นหาความจำที่ต้องการจากเซเรบรัม. ผู้ป่วยที่สูญเสียฮิปโปแคมปัสไปจะสูญเสียความสามารถในการสร้างความทรงจำใหม่.
3.2 คุณสมบัติความทั่วไปและการเลือกแบบจำลอง
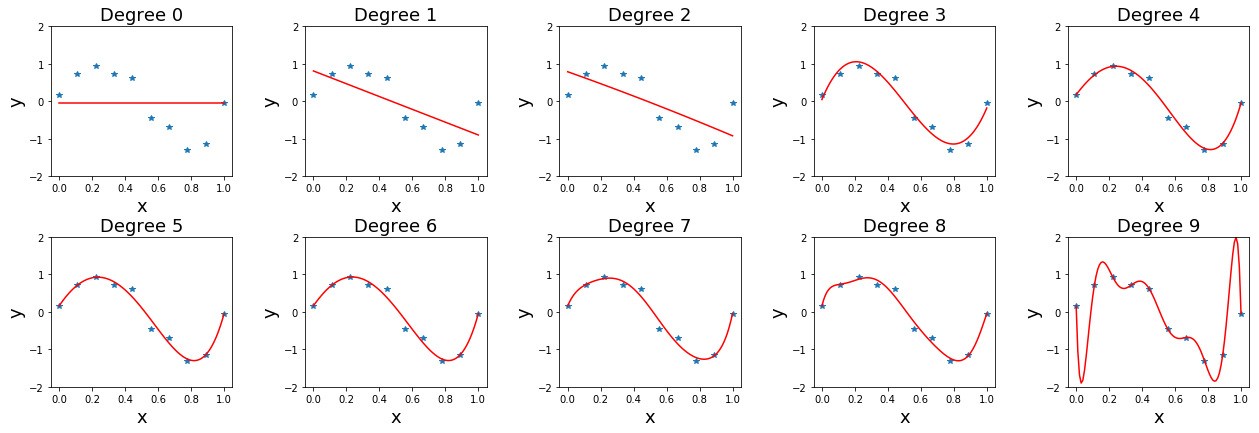
หัวข้อ 1.1 แสดงตัวอย่างของการปรับเส้นโค้ง ด้วยฟังก์ชันพหุนามระดับขั้นหนึ่ง. ระดับขั้นของฟังก์ชันพหุนาม เป็นอภิมานพารามิเตอร์ ของแบบจำลองพหุนาม. การสร้างแบบจำลองสามารถใช้ระดับขั้นใดก็ได้ แต่การเลือกระดับขั้นที่เหมาะสม เพื่อได้แบบจำลองทำนายที่ดี จะได้อภิปรายในหัวข้อนี้. รูป 1.5 แสดงพฤติกรรมการทำนายที่ระดับขั้นต่าง ๆ.
จากรูป 1.5 สังเกตว่า ระดับขั้นที่สูงขึ้นช่วยให้แบบจำลองยืดหยุ่นมากขึ้น และสามารถปรับตัวเข้าหาจุดข้อมูลได้ง่ายขึ้น และที่ระดับขั้นสูงมาก ๆ เช่น ที่ระดับขั้นเก้า ฟังก์ชันพหุนามสามารถปรับเข้าหาจุดข้อมูลได้ใกล้มาก ๆ. แต่ที่ระดับขั้นเก้า พฤติกรรมทำนาย ระหว่างจุดข้อมูลมีการเปลี่ยนแปลงรุนแรงมาก.
การสร้างแบบจำลองทำนาย ต้องการแบบจำลองทำนายที่มีคุณสมบัติความทั่วไป. คุณสมบัติที่แบบจำลองสามารถทำนายได้ดี แม้กับข้อมูลที่ไม่เคยเห็นมาก่อน จะเรียกว่า คุณสมบัติความทั่วไป (generalization). ปกติแล้ว ข้อมูลจะมีสัญญาณรบกวนประกอบเข้ามาด้วย แบบจำลองที่ดีควรจะจับสารสนเทศที่สำคัญของข้อมูล. เมื่อแบบจำลองปรับตัวเข้ากับข้อมูลที่ใช้ฝึก มากเกินไป แบบจำลองอาจจะจับสัญญาณรบกวนเข้าไปปนกับสารสนเทศที่สำคัญ ซึ่งจะส่งผลให้แบบจำลองสามารถทำนายข้อมูลที่ใช้ฝึกได้อย่างแม่นยำ แต่อาจไม่สามารถทำนายข้อมูลใหม่ได้ดี.
ตัวอย่างข้อมูลที่แสดงนี้ จริง ๆ แล้วสร้างมาจากความสัมพันธ์ \(y = \sin(2 \pi x) + \epsilon\) เมื่อสัญญาณรบกวน \(\epsilon\) สุ่มขึ้นมากจากการแจกแจงเกาส์เซียน ที่มีค่าเฉลี่ยเป็น \(0\) และค่าเบี่ยงเบนมาตราฐานเป็น \(0.3\). นั่นคือ \(\epsilon \sim \mathcal{N}(0, 0.3)\). รูป 1.6 แสดงพฤติกรรมการทำนาย เปรียบเทียบกับสารสนเทศที่สำคัญของข้อมูล (แสดงด้วยเส้นประสีดำ). แบบจำลองที่ดี คือแบบจำลองที่สามารถประมาณสารสนเทศที่สำคัญของข้อมูลได้ แต่ในทางปฏิบัติ การสร้างแบบจำลอง ไม่ได้รู้สารสนเทศที่สำคัญ เพราะหากรู้ ก็สามารถสร้างแบบจำลอง จากสารสนเทศที่สำคัญที่รู้นั้นได้โดยตรง. ดังนั้น การใช้งานแบบจำลองทำนาย ในทางปฏิบัติ ต้องการกลไก หรือกระบวนการที่จะทวนตรวจสอบว่า แบบจำลองยังมีคุณสมบัติความทั่วไปดีอยู่หรือไม่.
กระบวนการที่ใช้ตรวจสอบ คุณสมบัติความทั่วไป ที่ตรงมาตรงไปที่สุด คือการใช้ข้อมูลทดสอบ. ข้อมูลทดสอบ (test data) คือข้อมูลอีกชุด ที่ไม่ได้ถูกใช้ในกระบวนการฝึก เป็นข้อมูลที่แบบจำลองไม่เคยเห็นเลย จะใช้เพื่อทดสอบแบบจำลองเท่านั้น. เพื่อให้สามารถจำแนกได้ชัดเจน ว่ากำลังพูดถึงข้อมูลสำหรับจุดประสงค์ใดอยู่ ข้อมูลที่ใช้ฝึกแบบจำลอง จะเรียกว่า ข้อมูลฝึก (training data).
จากตัวอย่างการปรับเส้นโค้งข้างต้น สมมติมีข้อมูลทดสอบ ที่ได้แยกไว้คือ \((0.1,0.881)\), \((0.3,1.015)\), \((0.5,-0.152)\), \((0.7,-1.015)\), และ \((0.9,-0.537)\) รวม \(5\) จุดข้อมูล. รูป 1.8 ภาพ ก แสดงจุดข้อมูลฝึก (\(10\) จุด) และจุดข้อมูลทดสอบ (\(5\) จุด). ภาพ ข แสดงค่าผิดพลาดของแบบจำลองที่ระดับขั้นต่าง ๆ เมื่อทดสอบกับชุดข้อมูลฝึก และชุดข้อมูลทดสอบ.
 |
 |
| ก | ข |
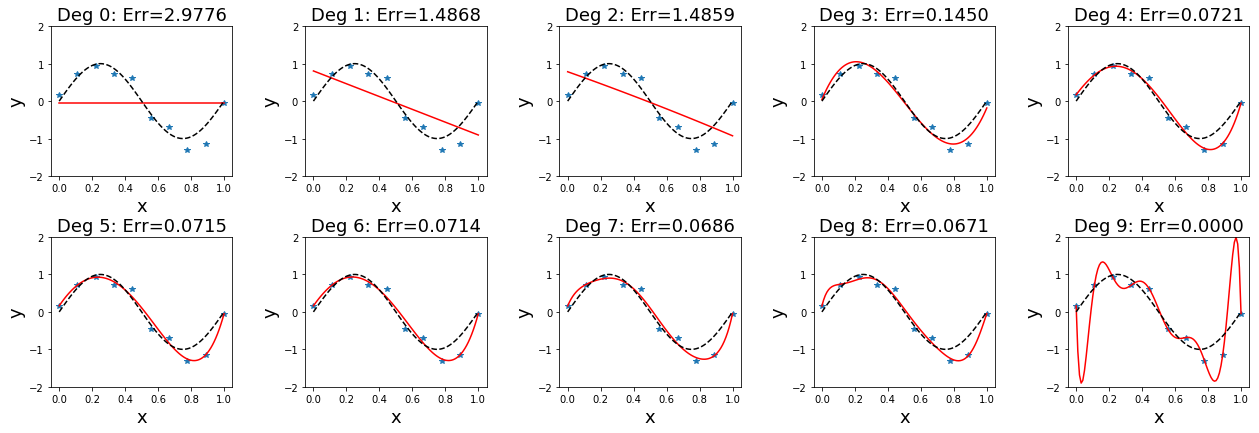
จาก ภาพ ข สังเกตว่า ค่าผิดพลาดเมื่อทดสอบกับชุดฝึก ซึ่งค่านี้มักเรียกว่า ค่าผิดพลาดชุดฝึก (training error) มีค่าลดลงเรื่อย ๆ เมื่อระดับขั้นเพิ่มขึ้น. แต่ค่าผิดพลาดเมื่อทดสอบกับชุดทดสอบ ซึ่งค่านี้มักเรียกว่า ค่าผิดพลาดชุดทดสอบ (test error) มีค่าลดลงจนต่ำสุดที่ ในตัวอย่างนี้ เป็นระดับขั้นสาม และค่ากลับเพิ่มขึ้น เมื่อระดับขั้นเพิ่มขึ้นหลังจากนั้น. ณ จุดที่ค่าผิดพลาดชุดฝึกต่ำลง แต่ค่าผิดพลาดชุดทดสอบกลับสูงขึ้น เป็นสัญญาณบ่งชี้ว่า แบบจำลองเริ่มเสียคุณสมบัติความทั่วไป ซึ่งมักเรียกว่า แบบจำลองเกิดการโอเวอร์ฟิต (overfitting) .
ผลจากค่าผิดพลาดชุดทดสอบ บ่งชี้ว่าแบบจำลองพหุนามระดับขั้นสี่ขึ้นไป เริ่มเกิดโอเวอร์ฟิต และแบบจำลองที่มีคุณสมบัติความทั่วไปดีที่สุดในการทดสอบนี้ คือ แบบจำลองพหุนามระดับขั้นสาม. หากสังเกต รูป 1.6 จะเห็นว่า ระดับขั้นสามให้การประมาณธรรมชาติจริงของข้อมูลดีที่สุด (พฤติกรรมของแบบจำลอง เส้นทึบแดง มีลักษณะใกล้เคียงกับธรรมชาติจริง เส้นประสีดำ มากกว่าระดับขั้นอื่น ๆ).
การโอเวอร์ฟิตของแบบจำลอง สัมพันธ์โดยตรงกับข้อมูล โดยเฉพาะกับจำนวนจุดข้อมูล. ฟังก์ชันพหุนามที่มีระดับขั้นสูง เรียกว่า เป็นแบบจำลองที่มี ความซับซ้อน (complexity) สูง. แบบจำลองที่มีความซับซ้อนสูง มีความยืดหยุ่นมาก. จำนวนจุดข้อมูลที่มีมากพอ จะช่วยให้เห็นสารสนเทศที่สำคัญ จากสัญญาณรบกวนที่ปนมาได้ชัดเจนขึ้น และช่วยการฝึกแบบจำลองที่มีความซับซ้อนสูง ให้มีคุณสมบัติความทั่วไปดีขึ้นได้.
 |
 |
 |
|
รูป 1.11 แสดงให้เห็นว่า ข้อมูลจำนวนมาก สามารถช่วยลดปัญหาโอเวอร์ฟิตได้. ภาพบนซ้ายแสดง ค่าผิดพลาดชุดทดสอบลดลงจนถึงค่อนข้างคงที่หลังจากระดับขั้นที่สาม.
ผู้เชี่ยวชาญบางคนแนะนำว่า จุดข้อมูลควรมีจำนวนไม่น้อยกว่า \(5\) เท่าของจำนวนพารามิเตอร์ของแบบจำลอง. ตัวอย่างเช่น ฟังก์ชันพหุนามระดับขั้นเก้า มีพารามิเตอร์ \(10\) ตัว ดังนั้นควรจะมีจุดข้อมูลไม่น้อยกว่า \(50\) จุดตามคำแนะนำนี้.
อย่างไรก็ตาม นอกจากการเพิ่มจำนวนจุดข้อมูล ยังมีกลไกอื่น ๆ อีก ที่สามารถช่วยลดปัญหาโอเวอร์ฟิต เมื่อใช้แบบจำลองที่มีความซับซ้อนสูงได้ เช่น การใช้แนวทางเบย์เชี่ยน (Bayesian) หรือ การทำเรกูลาไรซ์.
อีกประเด็นหนึ่งที่น่าสนใจ สังเกตระดับค่าผิดพลาดที่แสดงในรูป 1.11 เปรียบเทียบกับที่แสดงในรูป 1.8 ระดับค่าที่แสดงในรูป 1.8 (ภาพซ้าย) มีค่าค่อนข้างต่ำ (แกน \(y\) สูงสุดประมาณ \(3.0\)) ในขณะที่ ระดับค่าที่แสดงในรูป 1.11 (ภาพซ้ายบน) มีค่าสูงมาก (แกน \(y\) สูงสุดเกิน \(140\)). นั่นเป็นเพราะ ทั้งสองภาพวัดค่าผิดพลาดด้วย ผลรวมค่าผิดพลาด \(E = 0.5 \sum_n E_n\). โดยปกติแล้ว เมื่อจำนวนจุดข้อมูลมากขึ้น ผลรวมค่าผิดพลาดจะมากขึ้นตามไปด้วย. ในทางปฏิบัติ การประเมินผล มักรายงานผลด้วย ค่าความแม่นยำ (accurary) ซึ่งอาจวัดด้วย ค่าเฉลี่ยความผิดพลาดกำลังสอง (mean square error คำย่อ MSE) หรือ รากที่สองของค่าเฉลี่ยความผิดพลาดกำลังสอง (root mean square error คำย่อ RMSE) ที่ให้ผลคงเส้นคงวามากกว่าผลรวมค่าผิดพลาด. ค่าเฉลี่ยความผิดพลาดกำลังสอง คำนวณจาก \(\mathrm{MSE} = \frac{1}{N} \sum_{n=1}^N E_n\) เมื่อ \(N\) คือจำนวนจุดข้อมูล และค่าผิดพลาดกำลังสองของแต่ละจุดข้อมูล \(E_n = (\hat{y}_n - y_n)^2\) โดย \(\hat{y}_n\) กับ \(y_n\) คือค่าที่ทำนาย และค่าเฉลย สำหรับจุดข้อมูลที่ \(n^{th}\) ตามลำดับ. ในทำนองเดียวกัน รากที่สองของค่าเฉลี่ยความผิดพลาดกำลังสอง คำนวณจาก \(\mathrm{RMSE} = \sqrt{\frac{1}{N} \sum_{n=1}^N E_n}\).
3.2.0.0.1 การทำเรกูลาไรซ์.
การทำเรกูลาไรซ์ (regularization) เป็นวิธีหนึ่งที่นิยมใช้เพื่อช่วยลดปัญหาการโอเวอร์ฟิต. แนวทางหนึ่ง คือ การทำค่าน้ำหนักเสื่อม (weight decay) โดย การใส่พจน์เสมือนการลงโทษ เข้าไปในฟังก์ชันเป้าหมาย เพื่อจะถ่วงดุลไม่ให้พารามิเตอร์ของแบบจำลองมีค่าใหญ่เกินไป. สมการ \(\eqref{eq: bg regularization}\) แสดงฟังก์ชันเป้าหมาย ที่ประกอบด้วยพจน์ค่าผิดพลาดและพจน์ค่าน้ำหนักเสื่อม ซึ่งเป็นพจน์แรกและพจน์ที่สองทางขวามือ ตามลำดับ. นั่นคือ ฟังก์ชันเป้าหมาย \[\begin{eqnarray} \tilde{E}(\mathbf{w}) &=& \frac{1}{2} \sum_{n=1}^N \{ y(x_n, \mathbf{w}) - t_n \}^2 + \frac{\lambda}{2} \| \mathbf{w} \|^2 \label{eq: bg regularization} \end{eqnarray}\] เมื่อ \(\| \mathbf{w} \|^2 \equiv \mathbf{w}^T \mathbf{w} = w_0^2 + w_1^2 + \ldots + w_M^2\) และ พารามิเตอร์ \(\lambda\) ควบคุมสมดุลย์ระหว่างอิทธิพลของค่าผิดพลาดจากการทำนาย และอิทธิพลจากพจน์ค่าน้ำหนักเสื่อม. จากมุมมองของการหาค่าน้อยที่สุด พารามิเตอร์ \(\lambda\) อาจถูกเรียกเป็น ลากรานจ์พารามิเตอร์. บิชอบ ชี้ว่า บ่อยครั้งที่ พจน์ค่าน้ำหนักเสื่อม จะไม่รวม \(w_0\). หรือ ถ้ามี \(w_0\) ก็อาจจะมีลากรานจ์พารามิเตอร์เฉพาะของตัวเอง.
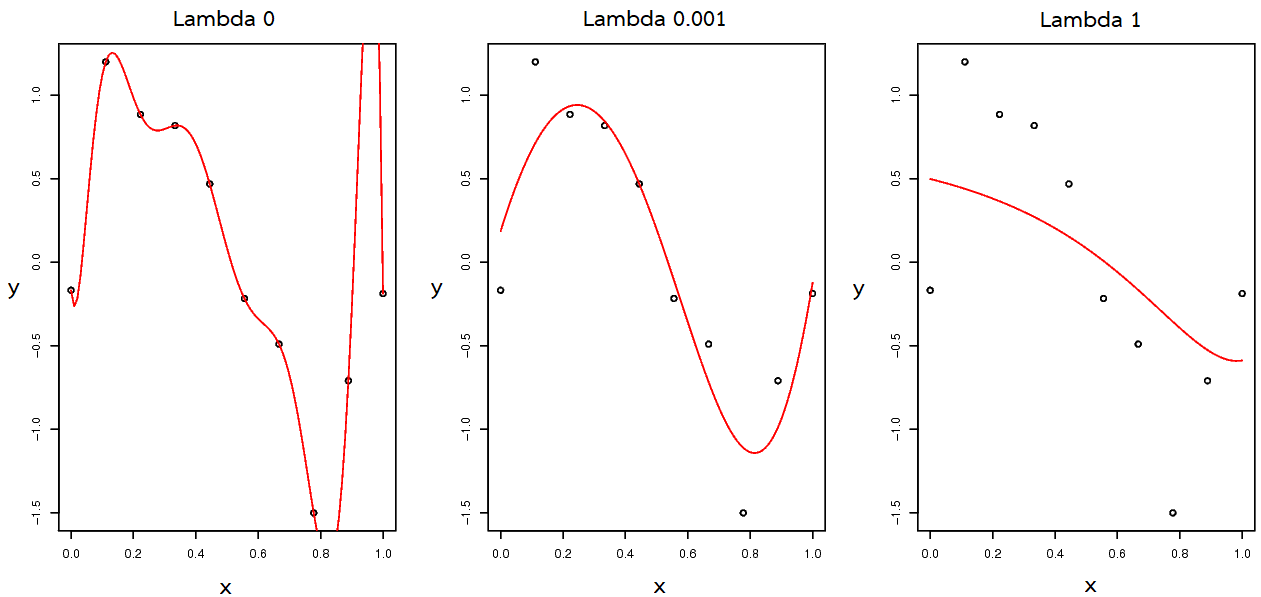
รูป 1.12 แสดงผลจากการทำเรกูลาไรซ์ ด้วยการใช้ค่าลากรานจ์ต่าง ๆ. ภาพซ้ายสุด \(\lambda = 0\) เทียบเท่ากับการไม่ได้ใช้วิธีค่าน้ำหนักเสื่อม. การโอเวอร์ฟิตเห็นได้ชัดในกรณีนี้. ภาพกลาง แสดงค่าลากรานจ์ที่เหมาะสม ค่าลากรานจ์พารามิเตอร์ที่เหมาะสม จะช่วยบังคับแบบจำลองที่มีความซับซ้อนสูง ให้ทำตัวเสมือนมีความซับซ้อนต่ำลง. ค่าประมาณจากแบบจำลอง (แสดงด้วยเส้นทึบสีแดง) มีลักษณะใกล้เคียงกับ \(\sin(2 \pi x)\) ที่ใช้สร้างจุดข้อมูล. แต่ถ้าหากใช้ลากรานจ์ค่าใหญ่เกินไป ก็อาจทำให้เกิดการอันเดอร์ฟิตได้ ดังแสดงในภาพขวาสุด.
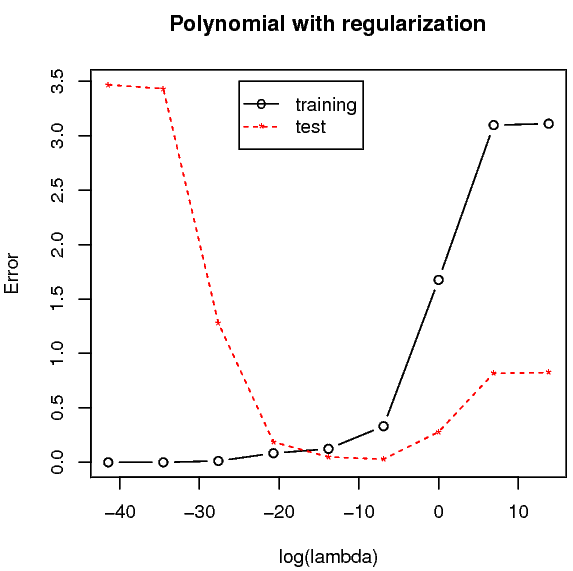
ตาราง 1.1 แสดงให้เห็นว่า ถ้าใช้ค่า \(\lambda\) ใหญ่พอดี การทำค่าน้ำหนักเสื่อม ช่วยควบคุมให้ค่าพารามิเตอร์ไม่ใหญ่เกินไปได้. แต่ถ้าใช้ค่า \(\lambda\) ใหญ่เกินไป ก็ทำให้ค่าพารามิเตอร์น้อยเกินไปได้ เช่นกัน. รูป 1.13 แสดงผลค่าผิดพลาดของแบบจำลองพหุนามระดับขั้นเก้า กับการทำค่าน้ำหนักเสื่อมที่ลากรานจ์ค่าต่าง ๆ เมื่อประเมินกับข้อมูลชุดฝึกหัดและชุดทดสอบ. สังเกตุค่าผิดพลาดของแบบจำลอง เมื่อประเมินกับชุดฝึกหัด ค่าผิดพลาดของแบบจำลองจะน้อยลง เมื่อใช้ลากรานจ์ค่าน้อย ๆ (ให้ผลคล้ายกับการใช้ฟังก์ชันพหุนามระดับขั้นสูง ๆ). ส่วนเมื่อประเมินกับชุดทดสอบ ค่าผิดพลาดของแบบจำลองจะลดลงต่ำสุดที่ค่าลากรานจ์ราว ๆ \(0.001\) หรือ \(\log(\lambda) \approx -6.91\).
| พารามิเตอร์ | \(\lambda = 0\) | \(\lambda = 10^{-5}\) | \(\lambda = 1\) |
|---|---|---|---|
| \(w_0\) | -0.17 | -0.04 | 0.5 |
| \(w_1\) | -18.6 | 11.85 | -0.47 |
| \(w_2\) | 1009.96 | -38.18 | -0.49 |
| \(w_3\) | -11723.66 | 37.64 | -0.35 |
| \(w_4\) | 64085.01 | -7.29 | -0.2 |
| \(w_5\) | -195203.42 | -20.61 | -0.07 |
| \(w_6\) | 349413.48 | -0.2 | 0.02 |
| \(w_7\) | -365010.66 | 20.7 | 0.1 |
| \(w_8\) | 205750.66 | 17.33 | 0.16 |
| \(w_9\) | -48302.79 | -21.36 | 0.21 |
[tbl: bg polynomial coeff regularization]
สำหรับการประเมินแบบจำลอง ปัจจัยสำคัญ คือ แบบจำลองสามารถทำนายข้อมูลที่ไม่เคยเห็นมาก่อนได้ดี หรือ แบบจำลองมีคุณสมบัติความทั่วไป. ดังนั้น เพื่อเลือกความซับซ้อนของแบบจำลอง เช่น การเลือกระดับขั้นของพหุนาม หรือการเลือกค่าลากรานจ์ของการทำค่าน้ำหนักเสื่อม จึงควรทำการวัดคุณสมบัติความทั่วไปของแบบจำลองที่ความซับซ้อนต่าง ๆ กัน. วิธีที่ง่ายและตรงไปตรงมาที่สุด ก็คือ การแบ่งข้อมูลออกเป็น \(2\) ชุด ได้แก่ ข้อมูลชุดฝึก ที่ใช้ฝึกแบบจำลอง นั่นคือใช้หาค่าของพารามิเตอร์ \(\mathbf{w}\) และชุดตรวจสอบ ที่ใช้เลือกความซับซ้อนของแบบจำลอง เช่น \(M\) หรือ \(\lambda\).
หลังจากเลือกแบบจำลองเสร็จแล้ว เพื่อประเมินแบบจำลอง ควรจะใช้ข้อมูลชุดทดสอบ ซึ่งเป็นข้อมูลอีกชุด สำหรับการทดสอบ. การที่ต้องใช้ชุดทดสอบที่แยกออกมานี้ เพื่อกันปัญหา ที่อาจจะเลือกแบบจำลองที่เกิดการโอเวอร์ฟิตกับชุดตรวจสอบได้. หากทำการเลือกแบบจำลองได้ดี ค่าผิดพลาดที่ประเมินกับข้อมูลชุดทดสอบ ไม่ควรห่างมากจากค่าผิดพลาดที่ประเมินกับข้อมูลชุดตรวจสอบ.
3.2.0.0.2 ครอสวาลิเดชั่น.
ถ้าข้อมูลมีจำนวนมาก การแบ่งบางส่วนของข้อมูลมาเป็นชุดตรวจสอบนั้น ไม่ได้ดูว่ามีปัญหาอะไร แต่หากข้อมูลมีปริมาณจำกัด ควรจะจัดการสถานการณ์อย่างไร เมื่อการฝึกแบบจำลองให้ดีต้องการข้อมูลจำนวนมาก แต่คุณภาพของการตรวจสอบเลือกความซับซ้อน และการทดสอบ ก็ต้องการข้อมูลจำนวนมากเช่นกัน. การแบ่งส่วนข้อมูลที่มีปริมาณน้อยอยู่แล้ว ยิ่งจะทำให้แต่ละส่วนมีปริมาณน้อยลงไปอีก. วิธีหนึ่งที่ออกแบบมาเพื่อบรรเทาปัญหานี้ คือ การทำครอสวาลิเดชั่น (cross-validation). แนวคิดคือ การสุ่มและใช้ผลเฉลี่ย โดยทำการฝึกแบบจำลองและการตรวจสอบหลาย ๆ ครั้ง แต่ละครั้ง แบ่งข้อมูลต่าง ๆ กันไป แล้วเอานำผลลัพธ์ที่ได้มาเฉลี่ยกัน เพื่อสรุปหาแบบจำลองที่มีคุณสมบัติความทั่วไปดีที่สุด. การดำเนินการ จะแบ่งข้อมูลออกเป็น \(K\) ส่วน แต่ละครั้งจะเลือกส่วนหนึ่งมาเป็นชุดตรวจสอบ และใช้ส่วนที่เหลือ (\(K-1\) ส่วน) สำหรับฝึกแบบจำลอง. เนื่องจาก การแบ่งข้อมูลเป็น \(K\) ส่วน วิธีนี้ มักถูกเรียกว่า วิธีครอสวาลิเดชั่น \(K\) พับ (K-fold cross-validation).
วิธีครอสวาลิเดชั่น \(K\) พับทำการฝึกและตรวจสอบ \(K\) ครั้ง ที่แต่ละครั้งจะเลือกส่วนที่ทำการตรวจสอบแตกต่างกัน. เมื่อทำจนครบทุกส่วนแล้ว จึงนำผลประเมินจากแต่ละครั้ง รวม \(K\) ค่า มาหาค่าเฉลี่ย เป็นค่าประเมินครอสวาลิเดชั่นของแบบจำลอง (cross-validation evaluation). ค่าประเมินครอสวาลิเดชั่นนี้ สามารถใช้เปรียบเทียบกับแบบจำลองอื่น (หรือแบบจำลองเดียวกันแต่ความซับซ้อนอื่น) เพื่อหาแบบจำลอง(หรือความซับซ้อน)ที่ดีที่สุด.
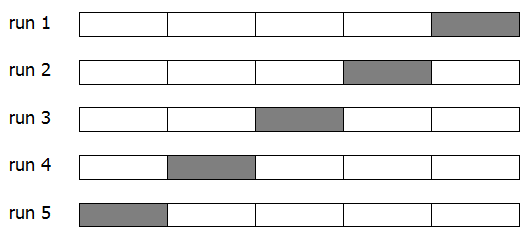
รูป 1.14 แสดงแผนภาพการแบ่งข้อมูลสำหรับวิธีครอสวาลิเดชั่น \(5\) พับ (\(K=5\)) และการจัดสรรข้อมูลสำหรับการฝึก และการตรวจสอบในแต่ละครั้ง. การฝึกและตรวจสอบแต่ละครั้ง จะเรียกเป็นวาลิเดชั่นรัน (validation run). ในภาพแสดง \(5\) วาลิเดชั่นรัน ที่รันแรก (Run 1) ฝึกแบบจำลองด้วยข้อมูล \(4\) ส่วนแรก และนำแบบจำลองที่ฝึกแล้ว ไปตรวจสอบกับข้อมูลส่วนหลังสุด (แรงเงาสีเข้มในรูป). รันที่สอง ฝึกแบบจำลองด้วยข้อมูลส่วนอื่นยกเว้นส่วนที่ \(4\) (แรงเงา) แล้วตรวจสอบกับส่วนที่ \(4\) ที่กันออกไว้. ทำเช่นนี้จนครบ \(5\) รัน แล้วนำเอาผลที่ได้มาเฉลี่ย.
ด้วยวิธีนี้ แต่ละรันจะฝึกแบบจำลองด้วยข้อมูลขนาด \(K-1\) ส่วนของที่มีอยู่ทั้งหมด \(K\) ส่วน และผลค่าผิดพลาดจากการตรวจสอบ เป็นค่าเฉลี่ยของค่าผิดพลาดที่ได้จากทุกส่วนของข้อมูล. วิธีครอสวาลิเดชั่นนี้ ทำให้เสมือนว่ามีข้อมูลมากขึ้น ทั้งการฝึกและการตรวจสอบ.
แม้วิธีครอสวาลิเดชั่น จะบรรเทาปัญหาของขนาดข้อมูลที่จำกัด และเป็นวิธีที่ใช้ข้อมูลได้อย่างคุ้มค่า แต่ข้อเสียของวิธีครอสวาลิเดชั่นคือ การที่ต้องทำการรันทั้งหมด \(K\) ครั้ง. ถ้าเลือกค่า \(K\) ใหญ่ ก็จะเปรียบเสมือนได้ใช้ข้อมูลปริมาณมากในการฝึก แต่ข้อเสีย คือเท่ากับเพิ่มจำนวนรันด้วย โดยเฉพาะ ถ้าการรันแต่ละครั้งใช้เวลามาก. กล่าวอีกนัยก็คือ วิธีครอสวาลิเดชั่น ใช้การคำนวณที่เพิ่มขึ้น เพื่อบรรเทาปัญหาข้อมูลปริมาณน้อย. ดังนั้น หากถ้าการรันแต่ละครั้งใช้การคำนวณมากอยู่แล้ว แนวทางของวิธีครอสวาลิเดชั่นอาจจะไม่เหมาะสม.
3.2.0.0.3 เกร็ดความรู้เซลล์ประสาท
(เรียบเรียงจาก และ )
สมองมนุษย์ประกอบด้วยเซลล์ชนิดต่าง ๆ มากมาย เช่น เส้นเลือด เซลล์เกลีย เซลล์ประสาท. เส้นเลือดทำหน้าที่รับส่งอากาศ น้ำ อาหาร. เซลล์เกลีย(neuroglia) ทำหน้าที่สนับสนุนต่าง ๆ รวมถึงการรักษาภาวะธำรงดุล (homeostasis) เพื่อให้ภายในสมองมีสภาวะที่เหมาะ เช่น การควบคุมระดับความเข้มข้นของโซเดียมและแคลเซียมไอออน. เซลล์ประสาททำหน้าที่หลักของสมอง ได้แก่การควบคุมระบบการทำงานต่าง ๆ ในร่างกายให้เป็นปกติ รวมไปถึง การให้ความสามารถในการจำ การเรียนรู้ การคิด การรับรู้ และการตอบสนอง.
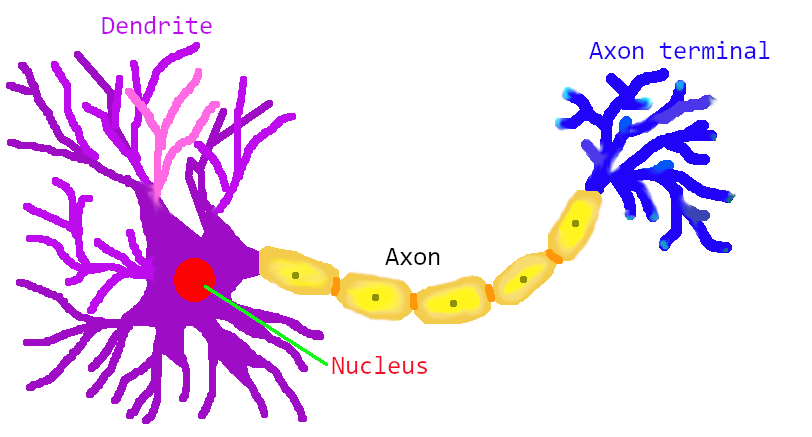
สมองมนุษย์มีเซลล์ประสาทอยู่ประมาณแสนล้านเซลล์ เซลล์ประสาทเองก็มีอยู่หลายประเภท แต่โครงสร้างพื้นฐานมีลักษณะคล้าย ๆ กัน. นั่นคือ เซลล์ประสาทแต่ละเซลล์ มีใยประสาทเพื่อรับสัญญาณเข้าสู่เซลล์ เรียกว่า เดนไดรต์ (dendrite). สัญญาณต่าง ๆ ทั้งสัญญาณกระตุ้นและสัญญาณยับยั้งที่เข้าสู่เซลล์ จะถูกนำมารวมกันที่นิวเคลียส และผลรวมของสัญญาณที่รับเข้ามา จะเป็นตัวตัดสินว่า เซลล์ประสาทนั้นจะอยู่ในสถานะถูกกระตุ้นหรือไม่. ถ้าเซลล์ประสาทอยู่ในสถานะถูกกระตุ้น มันจะส่งสัญญาณออกไปให้กับเซลล์ประสาทอื่น ๆ ที่รับสัญญาณจากมัน โดยส่งออกผ่านใยประสาทนำออกสัญญาณ เรียกว่า แอกซอน (axon). จุดต่อระหว่างแอกซอนของเซลล์ประสาทตัวหนึ่งกับเดนไดรต์ของเซลล์ประสาทอีกเซลล์หนึ่ง เป็นจุดประสานประสาทที่เรียกว่า ไซแนปส์ (synapse). แนวคิดพื้นฐานนี้เองที่ โรเซนแบลท (หัวข้อ 1.3) นำไปสร้างแบบจำลองเพอร์เซปตรอน (ดูรูป 1.17 และ 1.16 ประกอบ) เมื่อเปรียบเทียบเพอร์เซปตรอน (รูป 1.18) กับเซลล์ประสาท ผลคูณของอินพุตกับค่าน้ำหนักของเพอร์เซปตรอน (เช่น \(x_1 w_1\) และ \(x_2 w_2\)) เทียบได้กับ ความแรงของสัญญาณประสาท แต่ละสัญญาณที่รับเข้ามาผ่านไซแนปส์ แล้วเดินทางเข้าสู่นิวเคลียสของเซลล์ประสาท เพื่อไปรวมกับความแรงของสัญญาณประสาทที่รับเข้ามาผ่านไซแนปส์จุดอื่น ๆ. ความแรงของสัญญาณประสาท แต่ละสัญญาณที่รับเข้ามาผ่านไซแนปส์ จะขึ้นอยู่กับ สัญญาณที่ส่งมา (เปรียบเทียบกับ \(x_i\)) และ ความแข็งแรงในการเชื่อมต่อสัญญาณของไซแนปส์ (เปรียบเทียบกับ \(w_i\)).
โดยเฉลี่ยแล้ว เซลล์ประสาทแต่ละเซลล์จะมีไซแนปส์ประมาณห้าพันจุด ซึ่งนั่นคือเมื่อรวมแล้ว ในสมองมนุษย์หนึ่งคนจะมีการเชื่อมต่อประสาทอยู่ราว ๆ ห้าร้อยล้านล้านไซแนปส์. การรับส่งสัญญาณประสาทระหว่างเซลล์ประสาทมีหลายกลไก เช่น กลไกทางเคมี (ผ่านสารสื่อประสาท) กลไกทางไฟฟ้า และ กลไกเชิงภูมิคุ้มกัน. แต่กลไกหลักของการส่งสัญญาณประสาทคือกลไกทางเคมี ซึ่งคือการรับส่งสัญญาณประสาทระหว่างเซลล์ประสาทโดยดำเนินการผ่านสารสื่อประสาท (neurotransmitter). เซลล์ประสาทที่ส่งสัญญาณจะปล่อยสารสื่อประสาทออกมา ผ่านโปรตีนที่ทำหน้าที่ส่งสารสื่อประสาท. โปรตีนส่งสาร เรียกว่า ทรานสปอร์ตเตอร์ (neurotransmitter transporter). และเซลล์ประสาทที่รับสัญญาณ จะรับสารสื่อประสาทเหล่านั้น ด้วยโปรตีนที่ทำหน้าที่รับสารสื่อประสาท. โปรตีนรับสาร เรียกว่า รีเซปเตอร์ (receptor).
เมื่อรีเซปเตอร์ได้รับสารสื่อประสาท นั่นคือ โครงสร้างของสารสื่อประสาทจับกับโครงสร้างของรีเซปเตอร์ แล้วทำให้กลไกของรีเซปเตอร์เปิดทำงาน โมเลกุลที่จับกับรีเซปเตอร์ จะเรียกว่า ลิแกนต์ (ligand). กลไกของการจับตัวระหว่างรีเซปเตอร์กับลิแกนต์นี้ จะเป็นกลไกในลักษณะแม่กุญแจกับลูกกุญแจ (lock and key). นั่นคือ โครงสร้างของรีเซปเตอร์แต่ละชนิดจะจับตัวได้เฉพาะกับลิแกนต์ที่มีโครงสร้างที่เข้ากันได้เท่านั้น เช่น สารสื่อประสาทอาเซ็ตทิลคอลีน (acetylcholine) ซึ่งเป็นสารสื่อประสาทที่เซลล์ประสาทใช้ติดต่อกระตุ้นเซลล์กล้ามเนื้อ จะจับกับรีเซปเตอร์สำหรับอาเซ็ตทิลคอลีนได้เท่านั้น และ รีเซปเตอร์สำหรับสารสื่อประสาทตัวอื่น ก็ไม่อาจจับกับอาเซ็ตทิลคอลีนได้เช่นกัน. การเข้าใจกลไกการทำงานลักษณะนี้ ช่วยให้เภสัชศาสตร์สามารถออกแบบตัวยาที่เฉพาะเจาะจงกับสารสื่อประสาทเฉพาะตัวได้ เช่น ยาต้านอาการเศร้าซึม ฟลูโอเซตทีน (Fluoxetine) ที่เฉพาะเจาะจงกับสารสื่อประสาทเซอโรโทนิน (Serotonin).
หมายเหตุ เซลล์ประสาทแต่ละชนิดจะมีลักษณะเฉพาะตัวต่างกันและจะทำงานกับสารสื่อประสาทเฉพาะชนิด เช่น เซลล์ประสาทเซอโรโทนิน (serotonin neurons) ที่อยู่บริเวณดอร์ซอลราฟีนูเคลียส (dorsal raphe nucleus) ของก้านสมอง จะทำงานกับสารสื่อประสาทเซอโรโทนิน, เซลล์ประสาทซีเอ1พีรามิดอล (CA1 pyramidal neurons) ที่อยู่บริเวณซีเอ1 (CA1) ของฮิปโปแคมปัส จะทำงานกับสารสื่อประสาทกลูตาเมท(Glutamate), เซลล์ประสาทมิดเบรนโดพามิเนอจิก (midbrain dopaminergic neurons) ที่อยู่หลาย ๆ บริเวณรวมถึง พื้นที่เวนทรอลเทกเมนทอล (ventral tegmental area) ในสมองส่วนกลาง จะทำงานกับสารสื่อประสาทโดพามีน (Dopamine). เซลล์ประสาทบางชนิดทำงานกับสารสื่อประสาทมากกว่าหนึ่งชนิด เช่น เซลล์ประสาทหนามกลาง (medium spiny neurons) ที่อยู่บริเวณบาซอลแกงเกลีย ส่งสัญญาณออกผ่านกาบา (GABA) แต่สามารถรับสัญญาณผ่านสารสื่อประสาทหลายชนิดรวมถึงกลูตาเมทและโดพามีน.
 |
 |
| (ก) | (ข) |
3.3 โครงข่ายประสาทเทียม
โครงข่ายประสาทเทียม (Artificial Neural Network) เป็นแบบจำลองทำนาย ที่ใช้ลักษณะการคำนวณง่าย ๆ คล้าย ๆ กัน จำนวนมาก ที่เมื่อนำมารวมกันแล้ว ให้ผลโดยรวม เป็นแบบจำลองทำนายที่มีความสามารถสูง.
โครงข่ายประสาทเทียม มีอยู่หลายชนิด หนึ่งในชนิดที่สำคัญและได้รับความนิยมอย่างมาก คือ เพอร์เซปตรอนหลายชั้น. เพอร์เซปตรอนหลายชั้น (multi-layer perceptron คำย่อ MLP) ที่รวมการคำนวณของหน่วยคำนวณย่อย ที่เรียกว่า เพอร์เซปตรอน หลาย ๆ หน่วย เข้าด้วยกัน ในลักษณะเป็นชั้น ๆ.
หน่วยคำนวณย่อย เพอร์เซปตรอน (perceptron) ถูกพัฒนาโดยการเลียนแบบเซลล์ประสาทของสิ่งมีชีวิต. เซลล์ประสาทของสิ่งมีชีวิตมีอยู่หลายชนิด แต่มีลักษณะทั่ว ๆ ไป ดังแสดงในรูป 1.17. แต่ละเซลล์รับสัญญาณกระตุ้นจากเซลล์อื่น ๆ ผ่านเดนไดรต์ (dendrite) เมื่อผลรวมของสัญญาณกระตุ้นมากพอเซลล์จะเข้าสู่สถานะถูกกระตุ้น และส่งสัญญาณออกผ่านแอกซอน (axon) ไปให้เซลล์อื่น ๆ ต่อไป. ความแรงของสัญญาณกระตุ้นที่รับมาจากแต่ละเซลล์ก็ต่าง ๆ กันไป ขึ้นกับการเชื่อมต่อ ซึ่งความแข็งแรงของการเชื่อมต่อ ก็มีการปรับเปลี่ยนตามการใช้งาน.
แฟรงค์ โรเซนแบลท (Frank Rosenblatt) ออกแบบ สร้าง และได้สาธิตการทำงานของ เพอร์เซปตรอน ที่สร้างด้วยวงจรไฟฟ้า เพื่อจำลองการทำงานของเซลล์ประสาท ในปี 1957. รูป 1.18 แสดงโครงสร้างแนวคิดของเพอร์เซปตรอน.
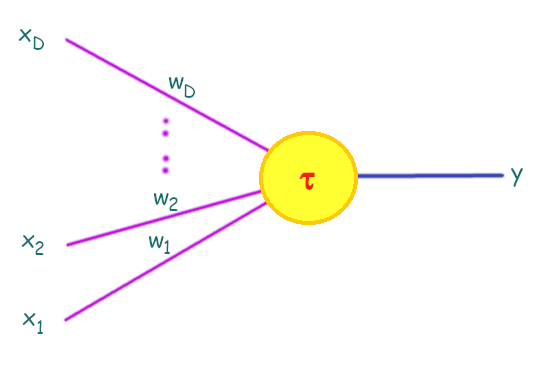
การคำนวณของเพอร์เซปตรอน ดำเนินการ โดย การนำอินพุตแต่ละตัว ไปคูณกับค่าน้ำหนักของอินพุตนั้น ๆ และนำค่าผลคูณทั้งหมดมาบวกกัน. แล้วหากผลบวกมีค่ามากพอ นั่นคือ มีค่าเท่ากับหรือมากกว่าค่าระดับกระตุ้น เพอร์เซปตรอนจะอยู่ในสถานะถูกกระตุ้น (ให้เอาต์พุตเป็น \(1\)) แต่หากผลบวกมีค่าน้อยกว่าระดับกระตุ้น เพอร์เซปตรอนจะอยู่ในสถานะไม่ถูกกระตุ้น (ให้เอาต์พุตเป็น \(0\)). ดังนั้น เอาต์พุตของเพอร์เซปตรอน สามารถเขียนดังสมการ \(\eqref{eq: perceptron neural sim}\). \[\begin{eqnarray} y = \left\{ \begin{array}{l l} 0 & \quad \mbox{เมื่อ} \quad w_1 x_1 + \cdots + w_D x_D < \tau , \\ 1 & \quad \mbox{เมื่อ} \quad w_1 x_1 + \cdots + w_D x_D \geq \tau . \end{array} \right. \label{eq: perceptron neural sim} \end{eqnarray}\] เมื่อ \(w_1, \ldots, w_D\) เป็นค่าน้ำหนัก (weights) ของอินพุต \(x_1, \ldots, x_D\) ตามลำดับ และ \(\tau\) คือ ค่าระดับกระตุ้น โดยผลลัพธ์ \(y = 1\) แทนสถานะการถูกกระตุ้น และ \(y = 0\) แทนสถานะไม่ถูกกระตุ้น. บางครั้ง อินพุต \(x_1, \ldots, x_D\) อาจถูกมองรวม คือมองเป็น อินพุต \(\boldsymbol{x} = [x_1, \ldots, x_D]^T\) โดย แต่ละตัว หรือแต่ละส่วนประกอบ \(x_i\) จะเรียกเป็น มิติ (dimension) หรือคุณลักษณะ (feature) ของอินพุต.
เพื่อความสะดวก นิยาม ไบอัส (bias) เป็น \(b = -\tau\) และเพอร์เซปตรอนสามารถเขียนได้เป็น \[\begin{eqnarray} y = \left\{ \begin{array}{l l} 0 & \quad \mbox{เมื่อ} \quad w_1 x_1 + \cdots + w_D x_D + b < 0, \\ 1 & \quad \mbox{เมื่อ} \quad w_1 x_1 + \cdots + w_D x_D + b \geq 0. \end{array} \right. \label{eq: perceptron bias} \end{eqnarray}\] และเมื่อมองในมุมที่กว้างขึ้น สมการ \(\eqref{eq: perceptron bias}\) สามารถเขียนได้เป็น \[\begin{eqnarray} y = h\left( \sum_{i=1}^D w_i x_i + b \right) \label{eq: ANN perceptron} \end{eqnarray}\] เมื่อ \(h\) เป็นฟังก์ชันกระตุ้น (activation function) ซึ่งอาจนิยามเป็น ฟังก์ชันจำกัดแข็ง (hard limit function หรือบางครั้งอาจเรียก ฟังก์ชันขั้นบันไดหนึ่งหน่วย unit step function) ได้แก่ \[\begin{eqnarray} h(a) = \left\{ \begin{array}{l l} 0 & \quad \mbox{เมื่อ} \quad a < 0,\\ 1 & \quad \mbox{เมื่อ} \quad a \geq 0. \end{array} \right. \label{eq: ANN hard limit} \end{eqnarray}\]
ในตอนนั้น งานของโรเซนแบลททำให้วงการคอมพิวเตอร์ โดยเฉพาะอย่างยิ่งวงการปัญญาประดิษฐ์ตื่นเต้นมาก ที่แนวทางนี้ อาจเป็นโอกาสที่มนุษย์จะสามารถสร้างเครื่องจักร ที่สามารถเลียบแบบการทำงานของสมองมนุษย์ได้ และเป้าหมายของปัญญาประดิษฐ์ และความฝันของวิทยาการคอมพิวเตอร์อาจจะสำเร็จได้ เกิดการคาดการณ์ถึงศักยภาพ ความสามารถต่าง ๆ ที่เครื่องคอมพิวเตอร์จะสามารถทำได้. แต่ความฝันและความหวังก็ล่มสลายไป หลังจาก มาร์วิน มินสกี้ (Marvin Minsky) และ เซมัวร์ ปาเปิต (Seymour Papert) ได้ร่วมกันเขียนหนังสือเพอร์เซปตรอนส์ ที่วิเคราะห์โครงสร้างและการทำงานของเพอร์เซปตรอน. ประเด็นสำคัญของหนังสือ คือ มินสกี้และปาเปิตถก และวิจารณ์ว่า เพอร์เซปตรอนนั้นสามารถทำได้แต่งานง่าย ๆ เช่นหากเป็นงานการจำแนกประเภท ก็สามารถทำงานได้กับปัญหาที่สามารถแบ่งได้ด้วยเส้นแบ่งตัดสินใจเชิงเส้นเท่านั้น ไม่สามารถทำงานที่ซับซ้อนกว่านั้นได้. พร้อมทั้งยังยกตัวอย่าง การทำงานของตรรกะ เอ็กซ์ออร์ (XOR หรือ exclusive OR) ที่เพอร์เซปตรอนไม่สามารถเลียบแบบได้. ตาราง 1.2 แสดงพฤติกรรมของตรรกะเอ็กซ์ออร์.
| \(x_1\) | \(x_2\) | \(y\) |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
[tbl: ANN XOR]
ผลจากคำวิจารณ์ของมินสกี้และปาเปิต นอกจากจะทำให้เพอร์เซปตรอนเสื่อมความสนใจแล้ว ยังทำให้เทคนิคทางด้านโครงข่ายประสาทเทียมทั้งหมด รวมไปถึงสาขาวิชาปัญญาประดิษฐ์ เสียความนิยมและเสื่อมความสนใจไปในช่วงหลายปีต่อจากนั้น จนเรียกกันว่า ช่วงเวลานั้นเป็น หน้าหนาวของปัญญาประดิษฐ์ (AI Winter). นอกจากคำวิจารณ์ของมินสกี้และปาเปิต เหตุผลอื่น ๆ ที่มีส่วนทำให้โครงข่ายประสาทเทียมเสียความนิยมไป ได้แก่ (1) การกำหนดโครงสร้างการเชื่อมต่อของโครงข่ายประสาทเทียม ที่ตอนนั้นยังใหม่มาก และยังไม่มีแนวทางที่ชัดเจน 1 และ (2) การใช้งานโครงข่ายประสาทเทียม จะต้องเลือกค่าน้ำหนัก และค่าไบอัสให้ถูกต้อง ซึ่ง ณ ช่วงเวลานั้น ยังไม่มีวิธีการที่มีประสิทธิภาพในการเลือกค่าน้ำหนัก และค่าไบอัส. (ยังไม่มีแม้แต่ หลักในการเลือกจำนวนเพอร์เซปตรอนที่เหมาะสมกับการใช้งาน.)
จนกระทั่งราวทศวรรษให้หลัง งานของเวอร์โบสและโดยเฉพาะอย่างยิ่งงานของกลุ่มของรูเมลาร์ต ฮินตัน และวิลเลี่ยม ที่ออกมาแสดงให้เห็นถึงประสิทธิผลของโครงข่ายประสาทเทียม พร้อมนำเสนอวิธีที่มีประสิทธิภาพ ในการหาค่าน้ำหนัก และค่าไบอัส ซึ่งงานเหล่านี้ ได้ช่วยฟื้นฟูความนิยมของโครงข่ายประสาทเทียมกลับมาใหม่.
เมื่อจะกล่าวไปแล้ว สิ่งที่มินสกี้กับปาเปิตวิจารณ์ว่า เพอร์เซปตรอนทำงานได้แต่งานง่าย ๆ ก็ไม่ได้ผิดซะทั้งหมด. เพียงแต่ว่า มินสกี้กับปาเปิตสรุปความเห็น จากการวิเคราะห์การทำงานของเพอร์เซปตรอนที่เป็นโครงข่ายชั้นเดียว. การทำงานของโครงข่ายสมองมนุษย์ไม่ได้เป็นชั้นเดียว ในลักษณะเดียวกัน โครงข่ายประสาทเทียมที่มีประสิทธิผล จะต้องมีโครงสร้างมากกว่าหนึ่งชั้น. นั่นก็คือ ที่มาของพัฒนาการต่อมา ได้แก่ เพอร์เซปตรอนหลายชั้น ซึ่งชื่อได้เน้นย้ำ ถึงการใช้โครงข่ายต่อเชื่อมกันในลักษณะหลายชั้น ของหน่วยคำนวณแบบเพอร์เซปตรอน.
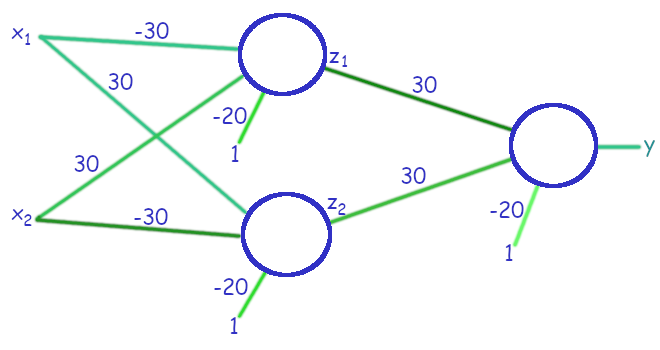
รูป 1.19 แสดงเพอร์เซปตรอนสองชั้น (two-layer perceptron) ที่สามารถเลียนแบบการทำงานของตรรกะเอ็กซ์ออร์ได้ โดยใช้เพอร์เซปตรอนสามตัว ต่อกันในลักษณะสองชั้นคำนวณ. เพอร์เซปตรอนแต่ละตัว อาจถูกเรียกว่า โหนด (node) หรือ หน่วยคำนวณ (unit). ผลลัพธ์จากโหนดในชั้นคำนวณแรก และส่งไปเป็นอินพุตให้กับโหนดในชั้นคำนวณที่สอง. การจัดโครงสร้างเป็นลักษณะชั้นคำนวณ (layer) แบบนี้ ช่วยให้โครงข่ายประสาทเทียมสามารถทำงานที่ซับซ้อนได้. เอาต์พุตของเพอร์เซปตรอนสองโหนดในชั้นแรก ซึ่งคือ \(z_1 = h(-30 x_1 + 30 x_2 - 20)\) และ \(z_2 = h(30 x_1 - 30 x_2 - 20)\) ทำหน้าที่เป็นอินพุตของเพอร์เซปตรอนตัวที่อยู่ชั้นที่สอง. เอาต์พุตของเพอร์เซปตรอนชั้นที่สอง ซึ่งเป็นชั้นสุดท้าย ที่จะใช้เป็นเอาต์พุตของทั้งโครงข่าย คำนวณด้วย \(y = h(30 z_1 + 30 z_2 - 20)\).
ตาราง 1.3 แจกแจงการทำงาน โดย \(a^{(1)}_1\) และ \(a^{(1)}_2\) เป็นตัวกระตุ้น (ผลรวมของสัญญาณกระตุ้น) ของโหนดตัวบน และของตัวล่างในชั้นที่หนึ่ง ตามลำดับ และ \(a^{(2)}\) เป็นของโหนดในชั้นที่สอง. สังเกตว่า ค่าน้ำหนักและไบอัส สามารถเปลี่ยนไปใช้ค่าอื่นได้ โดยที่การทำงานยังคงเดิมได้ เช่น อาจใช้ค่า \(20, -20, -10\) แทน \(30, -30, -20\) ในรูป 1.19 ได้ โดยพฤติกรรมการทำนายยังคงเดิม. นี่เป็น ลักษณะอย่างหนึ่งของโครงข่ายประสาทเทียม ที่ ค่าน้ำหนักและไบอัสที่ดีที่สุด มีได้หลายชุด.
| \(x_1\) | \(x_2\) | \(a^{(1)}_1\) | \(z_1\) | \(a^{(1)}_2\) | \(z_2\) | \(a^{(2)}\) | \(y\) |
|---|---|---|---|---|---|---|---|
| \(0\) | \(0\) | \(-30 (0) + 30 (0) - 20\) | \(h(-20)\) | \(30 (0) - 30 (0) - 20\) | \(h(-20)\) | \(30 (0) + 30 (0) - 20\) | \(h(-20)\) |
| \(= -20\) | \(= 0\) | \(= -20\) | \(= 0\) | \(= -20\) | \(= 0\) | ||
| \(0\) | \(1\) | \(-30 (0) + 30 (1) - 20\) | \(h(10)\) | \(30 (0) - 30 (1) - 20\) | \(h(-50)\) | \(30 (1) + 30 (0) - 20\) | \(h(10)\) |
| \(= 10\) | \(= 1\) | \(= -50\) | \(= 0\) | \(= 10\) | \(= 1\) | ||
| \(1\) | \(0\) | \(-30 (1) + 30 (0) - 20\) | \(h(-50)\) | \(30 (1) - 30 (0) - 20\) | \(h(10)\) | \(30 (1) + 30 (0) - 20\) | \(h(10)\) |
| \(= -50\) | \(= 0\) | \(= 10\) | \(= 1\) | \(= 10\) | \(= 1\) | ||
| \(1\) | \(1\) | \(-30 (1) + 30 (1) - 20\) | \(h(-20)\) | \(30 (1) - 30 (1) - 20\) | \(h(-20)\) | \(30 (0) + 30 (0) - 20\) | \(h(-20)\) |
| \(= -20\) | \(= 0\) | \(= -20\) | \(= 0\) | \(= -20\) | \(= 0\) |
[tbl: ANN MLP for XOR]
การคำนวณของโครงข่ายประสาทเทียม แบบเพอร์เซปตรอนหลายชั้น สรุปได้ดังสมการ \(\eqref{eq: mlp feedforward x}\) ถึง \(\eqref{eq: mlp feedforward y}\). \[\begin{aligned} z_j^{(0)} &= x_j &\mbox{สำหรับ }& j = 1, \ldots, D; \label{eq: mlp feedforward x} \\ a_j^{(q)} &= \sum_i z_i^{(q-1)} \cdot w_{ji}^{(q)} + b_j^{(q)} &\mbox{สำหรับ }& j = 1, \ldots, M_q; \label{eq: mlp feedforward a} \\ z_j^{(q)} &= h(a_j^{(q)}) &\mbox{สำหรับ }& j = 1, \ldots, M_q; \label{eq: mlp feedforward z} \\ \hat{y}_k &= z_k^{(L)} &\mbox{สำหรับ }& k = 1, \ldots, K \label{eq: mlp feedforward y} \end{aligned}\] เมื่อ \(q = 1, \ldots, L\) โดย \(L\) เป็นจำนวนชั้นคำนวณ และ \(\boldsymbol{x} = [x_1, \ldots, x_D]^T\) เป็นอินพุตของแบบจำลอง และ \(\boldsymbol{\hat{y}} = [\hat{y}_1, \ldots, \hat{y}_K]^T\) เป็นเอาต์พุตของแบบจำลอง.
ตัวแปร \(a_j^{(q)}\) คือตัวกระตุ้นของโหนดที่ \(j^{th}\) ในชั้นคำนวณที่ \(q^{th}\). การบวกในสมการ \(\eqref{eq: mlp feedforward a}\) ทำสำหรับทุกโหนดในชั้นก่อนหน้า นั่นคือ \(a_j^{(q)} = b_j^{(q)} + \sum_{i=1}^{M_{q-1}} z_i^{(q-1)} \cdot w_{ji}^{(q)}\) โดยกำหนด \(M_0 = D\). ชั้นคำนวณที่ \(q^{th}\) มีโหนด จำนวน \(M_q\) โหนด. พารามิเตอร์ \(w_{ji}^{(q)}\) เป็นค่าน้ำหนักสำหรับการเชื่อมต่อของโหนด \(j^{th}\) ในชั้น \(q^{th}\) กับโหนด \(i^{th}\) ในชั้นก่อนหน้า. พารามิเตอร์ \(b_j^{(q)}\) เป็นค่าไบอัสของโหนด \(j^{th}\) ในชั้น \(q^{th}\). ฟังก์ชัน \(h\) เป็นฟังก์ชันกระตุ้น.
ตัวแปร \(z_j^{(q)}\) เป็นเอาต์พุตของโหนด \(j^{th}\) ในชั้น \(q^{th}\) สำหรับ \(q = 1, \ldots, L\) โดยสมการ \(\eqref{eq: mlp feedforward x}\) นิยามเอาต์พุตของชั้น \(0^{th}\) เป็นอินพุตของแบบจำลอง เมื่อความกระทัดรัด.
เอาต์พุตของแบบจำลองคือ เอาต์พุตของโหนดต่าง ๆ ในชั้นสุดท้าย (ดังระบุในสมการ \(\eqref{eq: mlp feedforward y}\)) ดังนั้น \(M_L = K\) โดย \(K\) เป็นจำนวนมิติของเอาต์พุตที่ต้องการ. จำนวนชั้นคำนวณ และจำนวนโหนดในแต่ละชั้น เป็น อภิมานพารามิเตอร์ ของแบบจำลองเพอร์เซปตรอนหลายชั้น.
สมการ \(\eqref{eq: mlp feedforward x}\) ถึง \(\eqref{eq: mlp feedforward y}\) แสดงการคำนวณของเพอร์เซปตรอน ในรูปตัวแปรสเกล่าร์. การคำนวณของเพอร์เซปตรอน สามารถเขียนได้กระชับกว่า โดยเขียนในรูปเวกเตอร์และเมทริกซ์ ดังสมการ \(\eqref{eq: mlp feedforward a vec}\) และ \(\eqref{eq: mlp feedforward z vec}\) ซึ่ง การจัดรูปในลักษณะนี้จะเรียกว่า เวคตอไรเซชั่น (vectorization). \[\begin{aligned} \boldsymbol{a}^{(q)} &= \boldsymbol{W}^{(q)} \cdot \boldsymbol{z}^{(q-1)} + \boldsymbol{b}^{(q)} \label{eq: mlp feedforward a vec} \\ \boldsymbol{z}^{(q)} &= h(\boldsymbol{a}^{(q)}) \label{eq: mlp feedforward z vec}\end{aligned}\] สำหรับ \(q = 1, \ldots, L\) เมื่อ \(L\) คือจำนวนชั้นคำนวณ. ตัวแปร \(\boldsymbol{a}^{(q)} = [a^{(q)}_1, \;a^{(q)}_2, \ldots, \; a^{(q)}_{M_q}]^T\) คือตัวกระตุ้นของชั้นคำนวณ \(q^{th}\) ที่มี \(M_q\) โหนด. ตัวแปร \(\boldsymbol{z}^{(q)} = [z^{(q)}_1, \;z^{(q)}_2, \ldots, \; z^{(q)}_{M_q}]^T\) คือ ผลลัพธ์การกระตุ้นในชั้นคำนวณ \(q^{th}\) โดยกำหนดให้ อินพุตเสมือนมาจากโหนดชั้นศูนย์ นั่นคือ \(\boldsymbol{z}^{(0)} = \boldsymbol{x} = [x_1, \ldots, x_D]^T\) และเอาต์พุตของระบบ \([\hat{y}_1, \ldots, \hat{y}_K]^T = \boldsymbol{\hat{y}} \equiv \boldsymbol{z}^{(L)}\). เมทริกซ์ \(\boldsymbol{W}^{(q)} \in \mathbb{R}^{M_q \times M_{q-1}}\) และเวกเตอร์ \(\boldsymbol{b}^{(m)} \in \mathbb{R}^{M_q}\) คือค่าน้ำหนักและค่าไบอัสของชั้นคำนวณ \(q^{th}\) และ \(M_0 = D\) และ \(M_L = K\). ฟังก์ชัน \(h\) เป็นฟังก์ชันกระตุ้น ซึ่งสำหรับฟังก์ชันกระตุ้น \(h: \mathbb{R} \mapsto \mathbb{R}\) นิยามสัญกรณ์ เช่น \(h(\boldsymbol{a})\) เป็นปฏิบัติการที่มีลักษณะการคำนวณเชิงตัวต่อตัว (element-wise) เมื่อใช้กับเวกเตอร์ เมทริกซ์ หรือเทนเซอร์ (ยกเว้นจะระบุเป็นอย่างอื่น). นั่นคือ เช่น \(h([a_1, \ldots, a_m]^T) =[h(a_1), \ldots, h(a_m)]^T\).
สังเกตว่า การคำนวณจะดำเนินการในลักษณะคล้าย ๆ กัน เป็นชั้นคำนวณ อินพุตของระบบถูกป้อนให้กับชั้นคำนวณแรก เมื่อคำนวณผลจากชั้นหนึ่งเสร็จแล้ว ผลลัพธ์จะถูกใช้ป้อนเป็นอินพุตให้กับชั้นคำนวณต่อไป และดำเนินการเช่นนี้ต่อไปจนถึงชั้นคำนวณสุดท้าย ผลลัพธ์ของชั้นคำนวณสุดท้าย จะใช้เป็นเอาต์พุตของระบบ. เนื่องจากการคำนวณมีลักษณะที่คำนวณเป็นชั้น ๆ ผ่านไปทิศทางเดียว เพอร์เซปตรอนหลายชั้น บางครั้งอาจถูกเรียกว่า โครงข่ายแพร่กระจายไปข้างหน้า (feedforward network) . ชั้นคำนวณทั้งหมดที่อยู่ก่อนชั้นสุดท้าย นั่นคือ ชั้น \(q = 1, \ldots, L-1\) จะเรียกว่า ชั้นซ่อน (hidden layer) เนื่องจากเอาต์พุตของชั้นคำนวณเหล่านี้ ไม่ได้ใช้เป็นเอาต์พุตสุดท้ายของแบบจำลอง และโหนดต่าง ๆ ที่อยู่ในชั้นซ่อน จะเรียกว่า โหนดซ่อน (hidden node) หรือ หน่วยซ่อน (hidden unit). การเลือกอภิมานพารามิเตอร์ของเพอร์เซปตรอนหลายชั้น บางครั้งนิยม อ้างถึงจำนวนชั้นซ่อน เช่นในตัวอย่างรูป 1.18 อาจอ้างถึงเป็น โครงข่ายประสาทเทียม หนึ่งชั้นซ่อน ที่มีสองหน่วยซ่อน. หมายเหตุ ถึงแม้โครงข่ายประสาทเทียม จะมีหลายชนิด แต่เพอร์เซปตรอนหลายชั้น เป็นชนิดแรก และเป็นชนิดที่รู้จักกันอย่างกว้างขวาง บ่อยครั้งที่ คำว่า เพอร์เซปตรอนหลายชั้น, โครงข่ายประสาทเทียม หรือโครงข่ายแพร่กระจายไปข้างหน้า ถูกใช้แทนกัน.
ปัจจุบันโครงข่ายประสาทเทียม เป็นแบบจำลองได้ถูกนำไปใช้อย่างกว้างขวาง ในงานหลาย ๆ ลักษณะ เช่น การหาค่าถดถอย การจำแนกประเภท การประมาณฟังก์ชัน. นอกจากนั้น มีการศึกษาโครงข่ายประสาทเทียมในทางทฤษฎี และพิสูจน์ว่าโครงข่ายประสาทเทียม เป็นตัวประมาณค่าสากล (universal approximator) ซึ่งความหมายคือ โครงข่ายประสาทเทียม สามารถแทนฟังก์ชันใด ๆ ก็ได้ ที่ความละเอียดตามที่ต้องการ หากมีจำนวนหน่วยคำนวณมากเพียงพอ. ตามทฤษฎีแล้ว แค่โครงข่ายประสาทเทียมแบบสองชั้น ก็เป็นตัวประมาณค่าสากลได้แล้ว แต่การใช้โครงข่ายประสาทเทียมแบบลึก มีประโยชน์หลายอย่าง ดังที่จะอภิปรายในบทที่ [chapter: Deep Learning].
3.3.1 การฝึกโครงข่ายประสาทเทียม
กลับมาที่เรื่องการหาค่าน้ำหนักและค่าไบอัสที่เหมาะสม อย่างที่เห็นจากตัวอย่าง การที่โครงข่ายประสาทเทียมจะสามารถทำงานได้ตามที่ต้องการนั้น นอกจากโครงข่ายจะต้องมีโครงสร้างที่รองรับได้แล้ว (โครงสร้างเป็นลักษณะชั้น ๆ ต่อกันที่เหมาะสม และมีจำนวนหน่วยคำนวณเพียงพอ) ค่าน้ำหนักและค่าไบอัสต่าง ๆ จะต้องมีค่าที่เหมาะสมด้วย.
ค่าน้ำหนักและค่าไบอัส ของโครงข่ายประสาทเทียม ก็คือ พารามิเตอร์ต่าง ๆ ของแบบจำลอง. ดังนั้น การหาค่าน้ำหนักและค่าไบอัส ก็สามารถทำได้ในลักษณะเดียวกับ การหาค่าพารามิเตอร์ของฟังก์ชันพหุนามที่ได้อภิปรายในหัวข้อ 1.1. นั่นคือ การใช้วิธีของการหาค่าดีที่สุด และเช่นเดียวกัน การหาค่าน้ำหนักและค่าไบอัส จะเรียกว่า การฝึก.
อย่างไรก็ตาม เปรียบเทียบการฝึกแบบจำลองพหุนาม กับการฝึกโครงข่ายประสาทเทียม มีประเด็นที่น่าสนใจ คือ อนุพันธ์ของฟังก์ชันจุดประสงค์ต่อค่าพารามิเตอร์. การหาอนุพันธ์ เป็นกลไกสำคัญ สำหรับวิธีของการหาค่าดีที่สุดอย่างมีประสิทธิภาพ. เพอร์เซปตรอนใช้ฟังก์ชันจำกัดแข็ง เป็นฟังก์ชันกระตุ้น แต่เนื่องจาก ฟังก์ชันจำกัดแข็ง (สมการ \(\eqref{eq: ANN hard limit}\)) เป็นฟังก์ชันที่มีค่าไม่ต่อเนื่อง (ที่ \(a = 0\)) ทำให้ไม่สามารถหาค่าอนุพันธ์ของฟังก์ชันจำกัดแข็ง และส่งผลให้การหาค่าน้ำหนักที่เหมาะสมของเพอร์เซปตรอนทำได้ยาก.
ฟังก์ชันจำกัดแข็ง แม้จะเลียนแบบการทำงานของเซลล์ประสาท แต่ลักษณะทางคณิตศาสตร์ของมัน เป็นอุปสรรคสำคัญ ต่อการฝึกโครงข่ายประสาทเทียม. การสร้างแบบจำลองคณิตศาสตร์ เพื่อทำความเข้าใจเซลล์ประสาทชีวภาพ จัดอยู่ในขอบข่ายของประสาทวิทยาเชิงคำนวณ (computational neuroscience) ซึ่งเป็นสาขาเฉพาะ และอยู่นอกเหนือจากขอบเขตของหนังสือเล่มนี้. แม้กระนั้น ฟังก์ชันจำกัดแข็ง ก็ไม่ได้อธิบายการทำงานของเซลล์ประสาทชีวภาพได้เที่ยงตรงซะทีเดียว นอกจากนั้น สิ่งที่ต้องการจริง ๆ ในมุมมองทางวิศวกรรม ก็คือเครื่องมือที่ใช้งานได้ เช่น แบบจำลองที่มีความสามารถในการทำนายที่ดี.
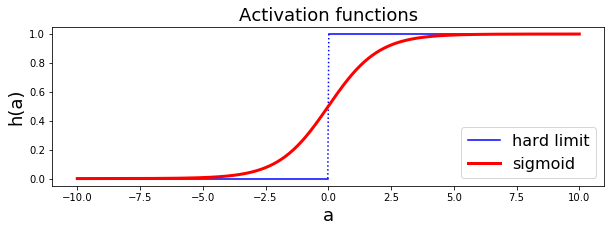
การฝึกโครงข่ายประสาทเทียมที่ใช้ฟังก์ชันจำกัดแข็งจะทำได้ยาก และไม่สามารถทำได้อย่างมีประสิทธิภาพ. เมื่อปัญหาอยู่ที่ฟังก์ชันจำกัดแข็ง วิธีแก้ก็แก้ที่ฟังก์ชันจำกัดแข็ง. สิ่งที่รูเมลาร์ต ฮินตัน และวิลเลี่ยม เสนอคือ ใช้ฟังก์ชันซิกมอยด์ (sigmoid function หรือบางครั้งเรียก logistic function หรือ logistic sigmoid function) เป็นฟังก์ชันกระตุ้น แทนฟังก์ชันจำกัดแข็ง. สมการ \(\eqref{eq: sigmoid}\) แสดงการคำนวณฟังก์ชันซิกมอยด์ \[\begin{eqnarray} \mathrm{sigmoid}(a) = \frac{1}{1 + \exp(-a)} \label{eq: sigmoid}. \end{eqnarray}\] ฟังก์ชันซิกมอยด์ เป็นฟังก์ชันค่าต่อเนื่อง ดังนั้นจึงสามารถหาอนุพันธ์ได้. รูป 1.20 แสดงค่าผลลัพธ์การกระตุ้นจากฟังก์ชันจำกัดแข็งเปรียบเทียบกับฟังก์ชันซิกมอยด์.
อย่างไรก็ตามแม้ ชื่อของเพอร์เซปตรอนจะเชื่อมโยงกับฟังก์ชันจำกัดแข็ง แต่ในทางปฏิบัติแล้ว โดยทั่วไป ชื่อเพอร์เซปตรอนหลายชั้น ก็มักอ้างถึงโครงข่ายประสาทเทียม ที่ใช้ฟังก์ชันซิกมอยด์เป็นฟังก์ชันกระตุ้น. นอกจากฟังก์ชันซิกมอยด์แล้ว ฟังก์ชันไฮเปอร์บอลิกแทนเจนต์ (hyperbolic tangent function) ซึ่งคำนวณโดย \(\tanh(x) = (e^x - e^{-x})/(e^x + e^{-x})\) ก็นิยมใช้เป็นฟังก์ชันกระตุ้นของโครงข่ายประสาทเทียม.
อีกประเด็น ฟังก์ชันกระตุ้น \(h\) ในสมการ \(\eqref{eq: mlp feedforward z}\) หรือ \(\eqref{eq: mlp feedforward z vec}\) ไม่จำเป็นต้องใช้เหมือนกันทุก ๆ ชั้นคำนวณ. นั่นคือ สมการ \(\eqref{eq: mlp feedforward z vec}\) อาจเขียนใหม่ เพื่อเน้นประเด็นนี้ ได้เป็น \(\boldsymbol{z}^{(q)} = h_q(\boldsymbol{a}^{(q)})\) เมื่อ \(h_q\) เป็นฟังก์ชันกระตุ้นของชั้น \(q^{th}\). ในทางปฏิบัติแล้ว ฟังก์ชันกระตุ้นของชั้นคำนวณสุดท้าย มักจะต่างจากฟังก์ชันกระตุ้นของชั้นอื่น ๆ. ชั้นคำนวณสุดท้าย มักถูกเรียกว่า ชั้นเอาต์พุต (output layer) เป็นชั้นที่จะเตรียมค่าของเอาต์พุต ให้อยู่ในรูปแบบที่ใกล้เคียง กับรูปแบบเอาต์พุตที่เหมาะสมกับภารกิจมากที่สุด. ฟังก์ชันกระตุ้นของชั้นเอาต์พุต เรียกสั้น ๆ ว่า ฟังก์ชันกระตุ้นเอาต์พุต (output activation function) จะถูกเลือกใช้ตามภาระกิจ และลักษณะค่าเอาต์พุตที่ต้องการ. ตัวอย่างเช่น การหาค่าถดถอย ซึ่งต้องการเอาต์พุต \(y \in \mathbb{R}\). ฟังก์ชันกระตุ้นเอาต์พุต นิยมใช้ฟังก์ชันเอกลักษณ์ (identity function). นั่นคือ \(h(a) = a\).
เมื่อเลือกใช้ฟังก์ชันกระตุ้นเป็นฟังก์ชันต่อเนื่องแล้ว การฝึกโครงข่ายประสาทเทียม ก็สามารถทำได้อย่างมีประสิทธิภาพ โดยอาศัยค่าอนุพันธ์. เช่นเดียวกับแบบจำลองทำนายอื่น ๆ การฝึกโครงข่ายประสาทเทียม คือ การหา \(\boldsymbol{\Theta}^\ast = \arg\min_{\boldsymbol{\Theta}} E\) เมื่อ \(E\) คือ ฟังก์ชันค่าผิดพลาดที่เป็นจุดประสงค์ และ \(\boldsymbol{\Theta}\) คือพารามิเตอร์ของแบบจำลอง ซึ่งสำหรับโครงข่ายประสาทเทียม จากสมการ \(\eqref{eq: mlp feedforward a}\) ก็คือ \(\boldsymbol{\Theta} = \{ w_{ji}^{(q)}, b_j^{(q)} \}\) โดย \(q=1,\ldots,L;\) \(j=1, \ldots, M_q;\) และ \(i = 1, \ldots, M_{q-1}\).
สำหรับงานการหาค่าถดถอย (regression) ซึ่งคือการทำนายเอาต์พุตที่ค่าเป็นจำนวนจริง ฟังก์ชันค่าผิดพลาด \(E\) สามารถนิยามด้วย ค่าเฉลี่ยค่าผิดพลาดกำลังสอง ดังแสดงในสมการ \(\eqref{eq: ann E}\) สำหรับข้อมูลจำนวน \(N\) จุดข้อมูล. \[\begin{aligned} E =& \frac{1}{N}\sum_{n=1}^N E_n \label{eq: ann E} \\ E_n =& \frac{1}{2} \|\boldsymbol{\hat{y}}(\boldsymbol{x}_n, \boldsymbol{\Theta}) - \boldsymbol{y}(n)\|^2 \label{eq: ann En}\end{aligned}\] เมื่อ \(\boldsymbol{y}(n)\) คือเฉลย หรือค่าตัวแปรตามจากจุดข้อมูลที่ \(n^{th}\) และ \(\boldsymbol{\hat{y}}(\boldsymbol{x}_n, \boldsymbol{\Theta})\) ที่อาจเขียนย่อเป็น \(\boldsymbol{\hat{y}}\) หากบริบทชัดเจน คือค่าที่แบบจำลองทำนายสำหรับจุดข้อมูลที่ \(n^{th}\) เมื่อใช้ค่าพารามิเตอร์เป็น \(\boldsymbol{\Theta}\). ค่าของ \(\boldsymbol{\hat{y}} = \boldsymbol{z}^{(L)}\) คำนวณได้จากสมการ \(\eqref{eq: mlp feedforward a vec}\) และ \(\eqref{eq: mlp feedforward z vec}\) โดยให้ \(\boldsymbol{z}^{(0)} = \boldsymbol{x}_n\) เมื่อ \(\boldsymbol{x}_n\) เป็นค่าตัวแปรต้นของจุดข้อมูลที่ \(n^{th}\).
การหา \(\boldsymbol{\Theta}^\ast = \arg\min_{\boldsymbol{\Theta}} E\) ที่มีประสิทธิภาพ ต้องการค่าเกรเดียนต์ \(\nabla_{\Theta} E = \frac{1}{N} \sum_{n=1}^N \nabla_{\Theta} E_n\) ซึ่งสามารถพิจารณาได้จาก \[\begin{aligned} \nabla_{\Theta} E_n =& \begin{bmatrix} \frac{\partial E_n}{\partial w_{1,1}^{(1)}} & \ldots & \frac{\partial E_n}{\partial w_{M_1,M_0}^{(1)}} & \frac{\partial E_n}{\partial b_1^{(1)}} & \ldots & \frac{\partial E_n}{\partial b_{M_1}^{(1)}} & \ldots & \frac{\partial E_n}{\partial w_{M_L,M_{L-1}}^{(L)}} & \ldots & \frac{\partial E_n}{\partial b_{M_L}^{(L)}} \end{bmatrix}^T \label{eq: backprop grad dEn}\end{aligned}\] หรืออาจเขียนย่อ ๆ เป็น \(\nabla_{\Theta} E_n = \left[ \frac{\partial E_n}{\partial w_{ji}^{(q)}}, \; \frac{\partial E_n}{\partial b_j^{(q)}} \right]^T\) โดย \(q=1,\ldots,L;\) \(i=1,\ldots,M_{q-1};\) และ \(j=1,\ldots,M_q\).
พิจารณาแต่ละส่วนประกอบของเกรเดียนต์ จากกฎลูกโซ่ของการหาอนุพันธ์ \(\frac{\partial E_n}{\partial w_{ji}^{(q)}} = \frac{\partial E_n}{\partial a_j^{(q)}} \cdot \frac{\partial a_j^{(q)}}{\partial w_{ji}^{(q)}}\) เพื่อความกระชับ สัญกรณ์ที่แสดง อาจละตัวยก \(\;^{(q)}\) ในกรณีที่บริบทชัดเจน นั่นคือ อนุพันธ์ดังกล่าวจะเขียนเป็น \[\begin{aligned} \frac{\partial E_n}{\partial w_{ji}} & = \frac{\partial E_n}{\partial a_j} \cdot \frac{\partial a_j}{\partial w_{ji}} & \mbox{และ} && \frac{\partial E_n}{\partial b_j} & = \frac{\partial E_n}{\partial a_j} \cdot \frac{\partial a_j}{\partial b_j} \label{eq: backprop dE/dw}\end{aligned}\]
กำหนดให้ \(\delta_j^{(q)} \equiv \frac{\partial E_n}{\partial a_j^{(q)}}\) และเมื่อบริบทชัดเจน อาจเขียนย่อเป็น \[\begin{aligned} \delta_j \equiv & \frac{\partial E_n}{\partial a_j} \label{eq: backprop delta}.\end{aligned}\]
จากสมการ \(\eqref{eq: mlp feedforward a}\) นั่นคือ \(a_j = \sum_i z_i^{(q-1)} \cdot w_{ji} + b_j\) ดังนั้น \[\begin{aligned} \frac{\partial a_j}{\partial w_{ji}} & = z_i^{(q-1)} & \mbox{และ} && \frac{\partial a_j}{\partial b_j} & = 1 \label{eq: backprop da/dw}\end{aligned}\] เมื่อแทนสมการ \(\eqref{eq: backprop da/dw}\) ลงในสมการ \(\eqref{eq: backprop dE/dw}\) จะได้ \[\begin{aligned} \frac{\partial E_n}{\partial w_{ji}^{(q)}} & = \delta_j^{(q)} \cdot z_i^{(q-1)} & \mbox{และ} && \frac{\partial E_n}{\partial b_j^{(q)}} & = \delta_j^{(q)} \label{eq: backprop dE/dw in delta}.\end{aligned}\]
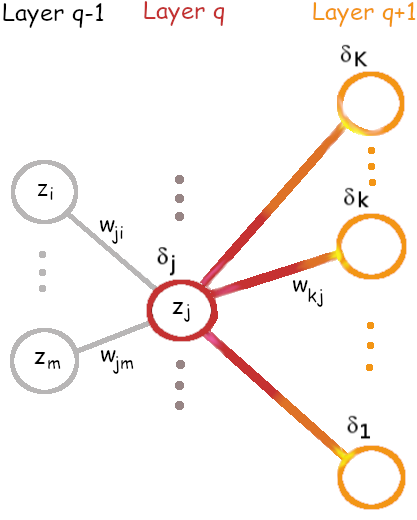
พิจารณา \(\delta_j^{(q)} = \frac{\partial E_n}{\partial a_j^{(q)}}\) ที่ชั้นเอาต์พุต \(q = L\) แทนค่า \(E_n\) จากสมการ \(\eqref{eq: ann En}\) และสำหรับการหาค่าถดถอย ฟังก์ชันกระตุ้นเอาต์พุตใช้ฟังก์ชันเอกลักษณ์ นั่นคือ \([\hat{y}_1, \; \ldots, \; \hat{y}_K]^T = [a_1^{(L)}, \; \ldots, \; a_K^{(L)}]^T\) จะได้ว่า \(\delta_k^{(L)} = \frac{\partial E_n}{\partial a_k^{(L)}}\) \(= \frac{\partial \frac{1}{2} \sum_m (\hat{y}_m - y_m)^2}{\partial a_k^{(L)}}\) และหลังจากหาอนุพันธ์จะได้ \[\begin{aligned} \delta_k^{(L)} & = \hat{y}_k - y_k \label{eq: backprop delta L}.\end{aligned}\] ที่ชั้นซ่อน \(q < L\) ตัวกระตุ้น \(a_j^{(q)}\) จะส่งผลต่อ \(E_n\) ผ่านโหนดต่าง ๆ ในชั้นถัดไป (รูป 1.21) ดังนั้น จากกฎลูกโซ่ของการหาอนุพันธ์ \[\begin{aligned} \delta_j^{(q)} & = \frac{\partial E_n}{\partial a_j^{(q)}} = \sum_m \frac{\partial E_n}{\partial a_m^{(q+1)}} \cdot \frac{\partial a_m^{(q+1)}}{\partial a_j^{(q)}} \label{eq: backprop dE/da chain rule}.\end{aligned}\] พจน์หน้า \(\frac{\partial E_n}{\partial a_m^{(q+1)}} = \delta_m^{(q+1)}\) มาจากชัดถัดไป. พจน์หลังคำนวณได้โดยเขียน \(a_m^{(q+1)}\) จากสมการ \(\eqref{eq: mlp feedforward a}\) และ \(\eqref{eq: mlp feedforward z}\) และหาอนุพันธ์ ซึ่งผลลัพธ์คือ \(\frac{\partial a_m^{(q+1)}}{\partial a_j^{(q)}}\) \(= w_{mj}^{(q+1)} \frac{\partial h(a_j^{(q)})}{\partial a_j^{(q)}}\). แทนทั้งสองพจน์นี้ในสมการ \(\eqref{eq: backprop dE/da chain rule}\) แล้วจะได้ว่า สำหรับชั้นซ่อน (\(q < L\)) แล้ว \[\begin{aligned} \delta_j^{(q)} & = h'(a_j^{(q)}) \cdot \sum_m \delta_m^{(q+1)} \cdot w_{mj}^{(q+1)} \label{eq: backprop delta q < L}\end{aligned}\] เมื่อ \(h'(a_j^{(q)}) = \frac{\partial h(a_j^{(q)})}{\partial a_j^{(q)}}\) คืออนุพันธ์ของฟังก์ชันกระตุ้น ที่ค่า \(a_j^{(q)}\). หมายเหตุ \(h'(a_j^{(q)})\) เป็นอนุพันธ์ของฟังก์ชันกระตุ้นของชั้น \(q^{th}\) และบางครั้ง อาจใช้สัญกรณ์ \(h_q'(a_j^{(q)}) = \frac{\partial h_q(a_j^{(q)})}{\partial a_j^{(q)}}\) ในกรณีที่อาจสับสน.
ทั้งหมดที่อภิปรายมา สรุปได้ว่า เกรเดียนต์ของโครงข่ายประสาทเทียม \(\nabla_{\Theta} E_n\) สามารถหาได้โดยกระบวนการดังนี้
ทำการคำนวณไปข้างหน้า (forward propagation หรือ forward pass) โดยคำนวณสมการ \(\eqref{eq: mlp feedforward x}\) ถึง \(\eqref{eq: mlp feedforward y}\). สิ่งที่ได้คือ ค่าที่ทำนาย \(\boldsymbol{\hat{y}}\) กับ ค่าตัวกระตุ้นและผลลัพธ์การกระตุ้นต่าง ๆ \(\boldsymbol{a}^{(q)}\) และ \(\boldsymbol{z}^{(q)}\) สำหรับ \(q = 1, \ldots, L\).
คำนวณค่า \(\delta_k^{(L)}\) สำหรับทุก ๆ โหนดเอาต์พุต \(k = 1, \ldots, K\) ตามสมการ \(\eqref{eq: backprop delta L}\). สิ่งที่ได้คือ \(\boldsymbol{\delta}^{(L)}\).
คำนวณค่า \(\delta_j^{(q)}\) สำหรับทุก ๆ โหนด ในทุก ๆ ชั้นซ่อน \(j = 1,\ldots,M_q; q = 1, \ldots, L-1\) ตามสมการ \(\eqref{eq: backprop delta q < L}\). สิ่งที่ได้คือ \(\boldsymbol{\delta}^{(q < L)}\).
คำนวณค่าอนุพันธ์ที่ต้องการ จากสมการ \(\eqref{eq: backprop dE/dw in delta}\). สิ่งที่ได้คือ \(\frac{\partial E_n}{\partial w_{ji}}\) และ \(\frac{\partial E_n}{\partial b_j}\) ค่าต่าง ๆ ทุกค่า ซึ่งรวมกันเป็นเกรเดียนต์ \(\nabla_{\Theta} E_n\).
เกรเดียนต์ \(\nabla_{\Theta} E_n\) ที่ได้สามารถนำไปใช้กับขั้นตอนวิธีการหาค่าดีที่สุด (optimization algorithm) เช่น วิธีลงเกรเดียนต์ที่อภิปรายในหัวข้อ [sec: optimization] ได้. กระบวนการหาเกรเดียนต์ \(\nabla_{\Theta} E_n\) ที่ได้อภิปรายมานี้ คือ วิธีการแพร่กระจายย้อนกลับ (error backpropagation หรือ backpropagation) คณะของ ที่รูเมลาร์ต เสนอในปี ค.ศ. 1986 และเป็นการค้นพบที่ฟื้นฟูความสนใจในโครงข่ายประสาทเทียมกลับมา หลังจากกว่าทศวรรษของหน้าหนาวของปัญญาประดิษฐ์.
3.3.1.0.1 เกร็ดความรู้จิตและการเรียนรู้
(เรียบเรียงจาก , , และ )
“ทุกสิ่งเริ่มที่จิต นำโดยจิต และสร้างโดยจิต” ธรรมบท
จิตคือสภาวะเชิงการรับรู้และเชิงสติปัญญา ซึ่งรวมถึง สติรู้ตัว การรับรู้สัมผัส ความรู้สึก อารมณ์ การคิด การตัดสินใจ การจดจำ การรับประสบการณ์ การเรียนรู้ และการตอบสนองต่อสภาวะแวดล้อม. ส่วนประกอบของจิตนั้น อาจจัดออกได้เป็น \(4\) หมวด. หมวดหนึ่ง วิญญาณ (vijnana) ซึ่งคือสติรู้ตัว (conciousness). หมวดสอง สัญญา (samjana) ซึ่งคือการรับรู้ (perception) ผ่านสัมผัสทางการมองเห็น สัมผัสทางการได้ยิน สัมผัสทางการได้กลิ่น สัมผัสการรับรส สัมผัสทางกาย และสัมผัสที่มาจากจิตเอง. จิตเองก็มีสัมผัสเช่นกัน ดังตัวอย่างของอาการแขนขาลวง (phantom limps) ที่เกิดในผู้ที่เสียแขนหรือขาไป แต่ภายหลังยังรู้สึกคันหรือเจ็บที่แขนหรือขาที่ไม่มีอยู่. แม้ว่าสาเหตุของอาการนี้ยังไม่มีคำอธิบายที่ทางการแพทย์ยอมรับร่วมกันอย่างกว้างขวาง แต่นายแพทย์วิลายานุร์ รามาฉันทรัน (Vilayanur S. Ramachandran) อธิบายว่า สัมผัสที่รู้สึกนั้นมาจากประสาทส่วนที่เคยทำงานกับแขนหรือขาส่วนนั้นขาดสัญญาณที่เคยได้รับ และอาจส่งสัญญาณออกมาทั้ง ๆ ที่ไม่ได้รับสัญญาณรับรู้จริง ๆ. จากทฤษฎีนั้น นายแพทย์รามาฉันทรันเสนอวิธีการบำบัดอาการแขนขาลวง โดยออกแบบกระบวนการให้ผู้มีอาการได้ฝึกประสาทรับรู้ใหม่ ซึ่งพบว่าได้ผลดีมาก. หากมองจากมุมมองทางวิศวกรรม สัญญาณที่ขาดหายไปจากแขนขาที่เสียไปนั้น อาจให้ผลในลักษณะคล้ายการที่วงจรไฟฟ้ารับอินพุตมาจากขั้วปลายที่ปล่อยลอยอยู่ ซึ่งขั้วปลายที่ปล่อยลอยอาจรับสัญญาณรบกวนเข้ามาแทนได้ การฝึกประสาทรับรู้ใหม่ ก็อาจคล้ายการต่อขั้วปลายนั้นเข้ากับสายสัญญาณเส้นอื่น เพื่อไม่ให้มีสายลอยที่จะรับสัญญาณรบกวนเข้ามา. หมวดสาม เวทนา (vedana) ซึ่งคือความรู้สึก (feeling) อารมณ์ ความชอบ ความไม่ชอบ ความวางเฉย. และ หมวดสี่ สังขาร (sankhara) ซึ่งคือการคิดและกระบวนการเชิงสติปัญญาอื่น ๆ (mental activity) ได้แก่ การตัดสินใจ การตอบสนองต่อสภาวะแวดล้อม การจดจำ การรับประสบการณ์ และการเรียนรู้.
นักประสาทวิทยาด้านสติปัญญาชั้นนำ รีเบกก้า แซก เชื่อว่า รูปแบบของกิจกรรมทางไฟฟ้าของเซลล์ประสาทเกี่ยวข้องโดยตรงกับ จิตของเรา เพียงแต่วงการวิทยาศาสตร์ยังไม่รู้อะไรมากเกี่ยวกับจิตและความสัมพันธ์ระหว่างรูปแบบของกิจกรรมทางไฟฟ้าและจิต
จากมุมมองของกิจกรรมทางไฟฟ้า การเรียนรู้ก็เหมือนการปรับเปลี่ยนวงจรหรือเปลี่ยนการเชื่อมต่อภายในวงจร ซึ่งส่งผลให้เกิดการปรับเปลี่ยนพฤติกรรมของกิจกรรมทางไฟฟ้า. สภาพพลาสติกของระบบประสาท (synaptic plasticity) คือ ความสามารถของระบบประสาทที่สามารถเพิ่มหรือลดความแข็งแรงของการเชื่อมต่อสัญญาณประสาทระหว่างเซลล์ได้. สภาพพลาสติกของระบบประสาทนี้เชื่อว่าเป็นคุณสมบัติที่อยู่เบื้องหลังความสามารถในการจดจำและการเรียนรู้ของสมอง. กลไกนี้เปรียบเทียบได้กับการปรับค่าน้ำหนักหรือการฝึกโครงข่ายประสาทเทียม แต่ประเด็นหนึ่งที่ต่างกันก็คือ การเปลี่ยนค่าน้ำหนักของโครงข่ายประสาทเทียมจะทำเฉพาะในขั้นตอนการฝึกโครงข่ายประสาทเทียม และค่าน้ำหนักที่ดีแล้วจะถูกตรึงให้คงค่าเหล่านั้นไว้คงที่ขณะใช้งาน. แต่ระบบประสาท(ทางชีวภาพ)จะเปลี่ยนแปลงตัวเองตลอดเวลา เปลี่ยนขณะเรียนรู้ เปลี่ยนขณะคิด เปลี่ยนขณะทำกิจกรรมต่าง ๆ เปลี่ยนขณะทำงาน เปลี่ยนขณะไม่ได้ทำงาน เปลี่ยนขณะเล่น เปลี่ยนขณะทำสิ่งที่มีประโยชน์ เปลี่ยนขณะพักผ่อน เปลี่ยนขณะนอนหลับ และที่สำคัญเปลี่ยนแม้แต่ขณะทำสิ่งที่เป็นโทษ เช่น เมื่อสิ่งที่เราคาดหวังไม่ได้ดั่งใจ แล้วเราไม่ชอบใจ ถ้าเราเลือกที่จะโกรธ สมองจะเรียนรู้การตอบสนองนั้น และ เมื่อเราทำแบบนั้นบ่อย ๆ เราก็จะกลายเป็นคนที่โกรธง่าย หรือกล่าวอย่างชัดเจนก็คือ เราฝึกสมองของเราให้เก่งที่จะอยู่ในสภาวะอารมณ์โกรธนั่นเอง.
กลไกเบื้องหลังการส่งสัญญาณของระบบประสาท กล่าวโดยคร่าว ๆ ก็คือ เมื่อสัญญาณจากนิวเคลียสของเซลล์ประสาทเดินทางถึงปลายแอกซอนซึ่งเป็นปลายสำหรับส่งสัญญาณออก สัญญาณซึ่งถ่ายทอดมาในรูปความต่างศักดิ์จะทำให้ช่องไอออนที่ควบคุมด้วยแรงดันไฟฟ้า (voltage-gated ion channel) ของปลายแอกซอนเปิดออก ทำให้แคลเซียมไอออน (calcium ion สัญญลักษณ์ \(Ca^{2+}\)) ซึ่งอยู่ในของเหลวรอบ ๆ เซลล์ ไหลเข้าสู่ปลายแอกซอน. แคลเซียมไอออนที่เข้าสู่ปลายแอกซอนจะทำปฏิกิริยากับโปรตีนและเอนไซม์ภายในแอกซอน ซึ่งส่งผลให้เกิดการปล่อยสารสื่อประสาทออกมา. สารสื่อประสาทที่ออกมา จะมีบางโมเลกุลที่ได้จับกับรีเซปเตอร์ที่ปลายเดนไดรต์ ซึ่งปลายเดนไดรต์คือปลายประสาทที่นำสัญญาณเข้าสู่เซลล์ประสาทตัวที่จะรับสัญญาณ. เมื่อรีเซปเตอร์จับกับสารสื่อประสาทแล้ว การจับตัวกันทำให้รีเซปเตอร์เปลี่ยนโครงสร้าง ซึ่งจะเปิดช่องให้ไอออนบวกไหลเข้าสู่เดนไดรต์ เมื่อไอออนบวกไหลเข้าสู่เดนไดรต์จะทำให้ความต่างศักดิ์ของเดนไดรต์จุดนั้นเปลี่ยนไป ซึ่งความต่างศักดิ์นี้เองเป็นสัญญาณที่จะถ่ายทอดต่อไปยังนิวเคลียสของเซลล์ประสาท.
สารสื่อประสาทเป็นกลไกหลักในการช่วยส่งสัญญาณประสาทข้ามเซลล์ประสาท แต่ตัวสารสื่อประสาทเองไม่ได้ถูกส่งเข้าไปในเดนไดรต์ของเซลล์ประสาทตัวรับ. มันทำหน้าที่เสมือนช่วยเปิดประตูให้ไอออนบวกได้เข้าไปในปลายเดนไดรต์ดังที่ได้อธิบายไปข้างต้น. หลังจากสารสื่อประสาทจับกับรีเซปเตอร์ได้สักพัก มันจะหลุดออกมา. สารสื่อประสาททั้งที่พึ่งหลุดมาจากการจับกับรีเซปเตอร์และที่ยังไม่ได้จับกับรีเซปเตอร์เลยจะถูกกำจัดออกไปโดยกลไกหลาย ๆ ชนิด เช่น การทำลายทิ้ง หรือ การที่ปลายแอกซอนดึงสารสื่อประสาทเหล่านี้กลับเข้าไปภายในเพื่อนำกลับไปใช้ใหม่.
การเรียนรู้หรือการปรับความแข็งแรงของการเชื่อมต่อสัญญาณระหว่างเซลล์ประสาท เกี่ยวข้องกับการปรับความสามารถในการรับส่งสัญญาณประสาทระหว่างเซลล์. เมื่อกล่าวถึงสัญญาณประสาทโดยละเอียดขึ้น สัญญาณประสาทจะถูกส่งในหลายรูปแบบ ขณะที่สัญญาณประสาทส่งผ่านเส้นทางจากนิวเคลียสของเซลล์ประสาทตัวหนึ่งไปสู่นิวเคลียสของเซลล์ประสาทอีกตัวหนึ่ง มีการเปลี่ยนรูปแบบอยู่หลายครั้ง. เมื่อเซลล์ประสาทอยู่ในสถานะถูกกระตุ้น นิวเคลียสของเซลล์จะส่งสัญญาณออกมาในรูปความถี่ของพัลส์. นั่นคือ นิวเคลียสของเซลล์ประสาทจะส่งสัญญาณในลักษณะพัลส์ (pulse) ซึ่งมักเรียกว่าศักยะงาน (action potential) เช่น ค่าความต่างศักย์ภายในเซลล์ประสาทจะมีค่าประมาณ \(-70\) มิลลิโวลต์เมื่อเทียบกับจุดภายนอกเซลล์ แต่เมื่อมีศักยะงานเกิดขึ้น ค่าความต่างศักย์นี้เพิ่มขึ้นอย่างรวดเร็วจากค่าพักตัวที่ประมาณ \(-70\) มิลลิโวลต์ ไปสูงสุดที่ประมาณ \(40\) มิลลิโวลต์ หลังจากนั้นจะลดค่าลงอย่างรวดเร็วมาที่ราว ๆ \(-90\) มิลลิโวลต์ และกลับมาจบที่ค่าพักตัวที่ประมาณ \(-70\) มิลลิโวลต์ โดยที่ศักยะงานแต่ละลูกจะยาวนานประมาณ \(4\) มิลลิวินาที. ความถี่หรือจำนวนศักยะงานต่อวินาที จะขึ้นกับความแรงของการกระตุ้น เช่น เซลล์โอล์แฟกตอรีคอร์เท็กซ์ไพรามิดอล (Olfactory Cortex pyramidal cell) ที่ทำงานเกี่ยวกับการรับรู้กลิ่น จะส่งศักยะงานออกมาที่ความถี่ประมาณ \(0.8\) ถึง \(2.0\) ลูกต่อวินาที ขณะหายใจปกติ แต่จะส่งศักยะงานความถี่ประมาณ \(4\) ถึง \(11\) ลูกต่อวินาที ขณะที่เรากำลังดมอะไรอยู่. สัญญาณในรูปความถี่นี้ได้มีการศึกษามาตั้งแต่ ค.ศ. 1926 ที่ เอเดรียนและโซตเตอมัน รายงานการศึกษาการกระตุ้นและสัญญาณไฟฟ้าเซลล์ประสาท โดยใช้ตุ้มน้ำหนักดึงกล้ามเนื้อของกบและวัดสัญญาณไฟฟ้าจากเนื้อเยื้อประสาทของมัน และพบความสัมพันธ์ที่ชัดเจน ระหว่างค่าน้ำหนักที่ยืดกล้ามเนื้อออก (ตัวแทนของปริมาณความแรงของการกระตุ้น) กับความถี่ของศักยะงานที่เกิดขึ้น. ศักยะงานนี้คือสัญญาณที่ถูกส่งออกจากนิวเคลียสผ่านไปที่ปลายแอกซอน สัญญาณที่ส่งผ่านออกจากปลายแอกซอนของเซลล์ตัวส่งเข้าไปสู่ปลายเดนไดร์ตของเซลล์ตัวรับจะส่งผ่านกลไกของสารสื่อประสาท และปลายเดนไดรต์รับสัญญาณประสาทเข้ามาในรูประดับความต่างศักย์ระหว่างภายในปลายเดนไดร์ตและภายนอก. รูปแบบที่เปลี่ยนไปของสัญญาณประสาทจากนิวเคลียสของตัวส่งไปจนถึงปลายแอกซอน (ในรูปศักยะงาน) ผ่านไซแนปซ์ (ในรูปสารสื่อประสาท) และรับเข้าสู่ปลายเดนไดร์ตไปจงถึงส่งเข้าไปสู่นิวเคลียสของตัวรับ (ในรูประดับความแรงของความต่างศักย์) รูปแบบเหล่านี้ เกี่ยวข้องสัมพันธ์กับทฤษฎีที่ใช้อธิบายกระบวนการเรียนรู้ของเซลล์ประสาท.
ทฤษฎีที่อธิบายการปรับความแข็งแรงของการเชื่อมต่อสัญญาณระหว่างเซลล์ประสาท กล่าวถึง กลไกหลัก \(2\) กลไก. นั่นคือ การเพิ่มความแข็งแรงเชิงประสาทระยะยาว (long-term synaptic potentiation คำย่อ LTP) และ การถดถอยความแข็งแรงเชิงประสาทระยะยาว (long-term synaptic depression คำย่อ LTD). จากงานศึกษาการเชื่อมต่อของเซลล์ในฮิปโปแคมปัส โดยเฉพาะ ไซแนปส์ที่เชื่อมต่อระหว่างเซลล์ประสาทในบริเวณซีเอ3 (CA3) ที่ส่งแอกซอน ซึ่งเรียกว่า แชฟเฟอร์คอแลทเตอรอล (Schaffer collaterals) ไปเชื่อมต่อกับเซลล์ประสาทในบริเวณซีเอ1 สรุปว่า เมื่อมีการกระตุ้นด้วยสัญญาณประสาทความถี่สูงผ่านไซแนปส์ ค่าความต่างศักย์ที่ได้รับที่ปลายเดนไดรต์ของไซแนปส์นั้นจะมีค่าเพิ่มขึ้นมาก และค่านั้นจะคงอยู่เป็นเวลานาน (หลายนาทีหรือหลายวัน หลังจากการกระตุ้นนั้น) โดยค่าความต่างศักย์ที่ปลายเดนไดรต์ที่เชื่อมต่อไซแนปส์อื่นจะไม่ได้รับผลกระทบ. สิ่งนี้เรียกว่า การเพิ่มความแข็งแรงเชิงประสาทระยะยาว.
ในทางกลับกัน เมื่อมีการกระตุ้นด้วยสัญญาณประสาทความถี่ต่ำผ่านไซแนปส์ ค่าความต่างศักย์ที่ได้รับที่ปลายเดนไดรต์ของไซแนปส์นั้นจะมีค่าลดลงมาก และค่านั้นก็คงอยู่เป็นเวลานาน โดยค่าความต่างศักย์ที่ปลายเดนไดรต์ที่เชื่อมต่อไซแนปส์อื่นจะไม่ได้รับผลกระทบ. สิ่งนี้เรียกว่า การถดถอยความแข็งแรงเชิงประสาทระยะยาว. ประเด็นสำคัญ คือ (1) มีการเปลี่ยนแปลงความแข็งแรงของไซแนปส์ระยะยาวเกิดขึ้น (2) ผลการเปลี่ยนแปลงความแข็งแรงขึ้นกับความถี่ (3) ผลการเปลี่ยนแปลงเกิดขึ้นเฉพาะตัวของไซแนปส์.
กลไกเบื้องหลัง นั้นอธิบายว่า ไซแนปส์ของแชฟเฟอร์คอแลทเตอรอล ทำงานผ่านสารสื่อประสาทกลูตาเมท และปลายประสาทของเซลล์ตัวรับที่ซีเอ1มีรีเซปเตอร์ที่ทำงานกับกลูตาเมทอยู่ \(2\) ชนิด คือ แอมปารีเซปเตอร์ (AMPA receptor) และ เอนเอมดีเอรีเซปเตอร์ (NMDA receptor). เมื่อปลายประสาทของเซลล์ที่ซีเอ3 จะส่งสัญญาณกระตุ้นผ่านไซแนปส์ มันจะปล่อยสารสื่อประสาท กลูตาเมท ออกมา. เมื่อกลูตาเมทจับกับแอมปารีเซปเตอร์ แอมปารีเซปเตอร์จะเปิดออก และด้วยคุณสมบัติของแอมปารีเซปเตอร์ โซเดียมไอออนจะไหลเข้าสู่ปลายเดนไดรต์ตัวรับที่ซีเอ1 แคลเซียมไอออนบางส่วนก็อาจไหลเข้าได้บ้างแต่ไม่มาก. แอมปารีเซปเตอร์ที่เปิดรับโซเดียมไอออนแล้วซักพักก็จะปิดลง. เมื่อกลูตาเมทจับกับเอนเอมดีเอรีเซปเตอร์ เอนเอมดีเอรีเซปเตอร์จะเปิดออกเช่นกัน แต่เอนเอมดีเอรีเซปเตอร์จะมีแมกนีเซียมไอออนปิดช่องอยู่ ทำให้ไอออนยังไม่สามารถไหลผ่านได้. หลังจากโซเดียมไอออนผ่านแอมปารีเซปเตอร์เข้าสู่เซลล์ซีเอ1 สักพักปริมาณโซเดียมไอออนจะถูกสูบออกโดยกลไกของโซเดียม-โปแตสเซียมปั๊ม (sodium-potassium pump) ซึ่งเป็นเอนไซมน์ที่ทำงานรักษาสมดุลของเซลล์.
3.3.1.0.2 การเพิ่มความแข็งแรงเชิงประสาทระยะยาว
หากการกระตุ้นมีความถี่สูงพอที่โซเดียมไอออนที่ไหลเข้ามาจะสะสมได้ (ความถี่สูงพอที่จะสะสมโซเดียมไอออน ที่เหลือจากการสูบออกของโซเดียม-โปแตสเซียมปั๊ม) ปริมาณโซเดียมไอออนที่เพิ่มขึ้นมาก จะเพิ่มระดับแรงดันไฟฟ้าสถิตย์ขึ้น. และเมื่อไฟฟ้าสถิตย์มากพอ มันจะสร้างแรงที่จะผลักแมกนีเซียมไอออน ที่ปิดเอนเอมดีเอรีเซปเตอร์ออกไปได้. เมื่อแมกนีเซียมหลุดออกไป แคลเซียมไอออนก็สามารถผ่านเข้ามาทางเอนเอมดีเอรีเซปเตอร์ได้. แคลเซียมไอออนที่ไหลเข้าปริมาณมากจะช่วยเพิ่มค่าความต่างศักย์ที่ได้รับที่ปลายเดนไดรต์ขึ้นไป. นอกจากนั้นแคลเซียมไอออนปริมาณมากจะจับกับโปรตีนคีเนส (Protein kinases) ซึ่งส่งผลให้เกิดการสร้างแอมปารีเซปเตอร์และติดตั้งแอมปารีเซปเตอร์ที่สร้างใหม่ เข้าไปที่ปลายเชื่อมประสาท ทำให้จำนวน แอมปารีเซปเตอร์เพิ่มขึ้น. ผลการเพิ่มแอมปารีเซปเตอร์จากกระบวนการนี้ จะคงอยู่เพียงแค่เวลาสั้น ๆ ไม่กี่ชั่วโมงเท่านั้น แต่หากมีแคลเซียมไอออนไหลเข้ามาในปริมาณมากเป็นระยะเวลานานพอ (มีการกระตุ้นด้วยสัญญาณประสาทความถี่สูงเป็นระยะเวลานาน) จะส่งผลต่อเนื่องไปจนทำให้เกิดการเพิ่มปัจจัยการลอกรหัสดีเอ็นเอ (transcription factor) ซึ่งส่งผลต่อการแสดงออกของยีน (gene expression) และทำให้เกิดการสร้างโปรตีนที่ทำให้เกิดทั้งแอมปารีเซปเตอร์ใหม่เพิ่มขึ้น และ โกรทแฟคเตอร์ (growth factor) ที่จะไปทำให้เกิดการสร้างไซแนปส์ใหม่เพิ่มขึ้น ซึ่งผลจากกระบวนการนี้จะยาวนานและคงทนมาก.
3.3.1.0.3 การถดถอยความแข็งแรงเชิงประสาทระยะยาว
สำหรับการกระตุ้นที่มีความถี่ต่ำ จะส่งผลให้ปริมาณของแคลเซียมไอออนอยู่ในระดับต่ำ. ปริมาณของแคลเซียมไอออนที่อยู่ในระดับต่ำจะไปกระตุ้นการทำงานของเอนไซม์ฟอสเฟตเตส (phosphatase) ซึ่งส่งผลไปลดจำนวนแอมปารีเซปเตอร์ที่ทำงานได้ลง.
การเพิ่มความแข็งแรงเชิงประสาทระยะยาว และ การถดถอยความแข็งแรงเชิงประสาทระยะยาว ต่างก็มีปัจจัยมาจากปริมาณแคลเซียมไอออนในปลายไซแนปส์ตัวรับ โดย ปริมาณแคลเซียมไอออนในระดับสูงจะทำให้เกิดการเพิ่มความแข็งแรงเชิงประสาทระยะยาว และ ปริมาณแคลเซียมไอออนในระดับต่ำจะทำให้เกิดการถดถอยความแข็งแรงเชิงประสาทระยะยาว. ระดับที่เป็นขีดแบ่งระหว่างการเพิ่มและการถดถอยนี้ เชื่อว่าน่าจะเปลี่ยนแปลงตามสภาวะของเซลล์ในลักษณะที่ช่วยรักษาสมดุลย์ (ทฤษฎีบีซีเอ็ม BCM theory) ได้แก่ การเปลี่ยนแปลงในลักษณะการป้อนกลับเชิงลบ (negative feedback) เช่น เมื่อไซแนปส์อยู่ในภาวะการเพิ่มความแข็งแรงเชิงประสาทระยะยาว ระดับขีดแบ่งนี้จะสูงขึ้น เพื่อช่วยลดความเสี่ยงของการเพิ่มมหาศาลลง และ เมื่อไซแนปส์อยู่ในภาวะการถดถอยความแข็งแรงเชิงประสาทระยะยาว ระดับขีดแบ่งนี้น่าจะลดลงเพื่อช่วยลดความเสี่ยงของการถดถอยจนสูญเสียการเชื่อมต่อ.
จากสภาพพลาสติกของระบบประสาทและทฤษฎีบีซีเอ็ม เราอาจกล่าวได้ว่า การเรียนรู้ที่มีประสิทธิภาพคือ การเรียนรู้ต่อเนื่อง สลับกับการหยุดพักผ่อน เพื่อให้เกิดการกระตุ้นประสาทต่อเนื่องยาวนานเพียงพอ ที่จะทำให้เกิดการสร้างการเชื่อมต่อใหม่ และ หยุดพักเพื่อให้ระดับขีดแบ่งปรับตัวลงมา ทำให้การสร้างการเชื่อมต่อใหม่ทำได้ง่ายขึ้น เพราะ การเรียนรู้ต่อเนื่องเป็นเวลานานเกินไป จะเพิ่มระดับขีดแบ่งซึ่งจะทำให้การเข้าสู่ภาวะการเพิ่มความแข็งแรงเชิงประสาทระยะยาวทำได้ยากขึ้น.
“Never go to excess, but let moderation be your guide.”
—Marcus Tullius Cicero
“ทำสิ่งใดอย่ามากเกินไป ให้ความพอดีเป็นตัวชี้ทาง.”
—-มาร์คัส ทูลลิอุส ซิเซอโร
3.3.2 การฝึกแบบหมู่กับการฝึกแบบออนไลน์
ค่าเกรเดียนต์ที่คำนวณได้จากวิธีการแพร่กระจายย้อนกลับ สามารถนำมาช่วยการฝึกโครงข่ายประสาทเทียมได้. แต่สมการเกรเดียนต์ของโครงข่ายประสาทเทียม ต่างจากสมการเกรเดียนต์ของฟังก์ชันพหุนาม. คำตอบของ เกรเดียนต์ฟังก์ชันพหุนามเป็นศูนย์ สามารถแก้สมการ เพื่อคำนวณหาค่าพารามิเตอร์ของฟังก์ชันพหุนามได้ทันที (คำตอบ สามารถเขียนอยู่ในรูปแบบปิดทางคณิตศาสตร์ได้). แต่สำหรับโครงข่ายประสาทเทียม คำตอบ ไม่สามารถหาได้โดยตรงจากการแก้สมการคณิตศาสตร์ และต้องใช้ขั้นตอนวิธีมาช่วย. ขั้นตอนวิธีการหาค่าดีที่สุด เช่น วิธีลงเกรเดียนต์ สามารถนำมาช่วยแก้ปัญหานี้ได้.
การนำขั้นตอนวิธีการหาค่าดีที่สุดไปใช้กับการฝึกแบบจำลอง มีประเด็นที่น่าสนใจคือ จังหวะการปรับค่าพารามิเตอร์ ควรทำบ่อยขนาดไหน. ตัวอย่างเช่น วิธีลงเกรเดียนต์ ปรับค่าพารามิเตอร์ด้วยสมการ \(\eqref{eq: opt gd}\) ที่นำมาเขียนในพจน์ของโครงข่ายประสาทเทียม \[\begin{aligned} \boldsymbol{\Theta}^{(i)} &= \boldsymbol{\Theta}^{(i-1)} - \alpha \cdot \nabla_{\Theta} E \left(\boldsymbol{\Theta}^{(i-1)}\right) \label{eq: gd ann}\end{aligned}\] เมื่อ \(\boldsymbol{\Theta}^{(i)}\) คือค่าพารามิเตอร์ของแบบจำลอง ที่ได้จากการคำนวณรอบที่ \(i^{th}\). ค่าสเกล่าร์ \(\alpha\) คือขนาดก้าว ซึ่งสำหรับการฝึกแบบจำลอง นิยมเรียกว่า อัตราเรียนรู้ (learning rate). เวกเตอร์ \(\nabla E_{\Theta} \left(\boldsymbol{\Theta}^{(i-1)}\right)\) เป็นค่าเกรเดียนต์ ณ ค่าพารามิเตอร์ก่อนการคำนวณรอบที่ \(i^{th}\). การคำนวณแต่ละรอบ จะเรียกว่า สมัย (epoch) .
หากตีความตรงตัว จะได้การปรับค่าน้ำหนัก ตามสมการ \(\eqref{eq: gd ann}\). การปรับค่าพารามิเตอร์ ที่ปรับทีเดียว ในแต่ละสมัย โดย การปรับ ใช้ค่าเฉลี่ยของเกรเดียนต์ที่คิดจากจุดข้อมูลฝึกทุกจุด. การปรับค่าน้ำหนักในลักษณะนี้ จะเรียกว่า การฝึกแบบหมู่ (batch training).
แต่จากสมการ \(\eqref{eq: ann E}\) นั้นเท่ากับ \(\nabla_{\Theta} E = \frac{1}{N} \sum_n \nabla_{\Theta} E_n\) เมื่อ \(N\) คือจำนวนจุดข้อมูล ในชุดข้อมูลฝึก ดังนั้น \[\begin{aligned} \boldsymbol{\Theta}^{(i)} &= \boldsymbol{\Theta}^{(i-1)} - \alpha \cdot \frac{1}{N} \sum_{n=1}^N \nabla_{\Theta} E_n \left(\boldsymbol{\Theta}^{(i-1)}\right) \label{eq: gd batch}.\end{aligned}\]
หากดัดแปลงเล็กน้อย โดยการปรับค่าพารามิเตอร์ให้ถี่ขึ้น คือการปรับค่าพารามิเตอร์ แต่ละครั้งสำหรับแต่ละจุดข้อมูล ดังแสดงในสมการ \(\eqref{eq: gd online}\) และจะปรับค่าพารามิเตอร์ \(N\) ครั้งในแต่ละสมัย. การปรับค่าพารามิเตอร์ในลักษณะเช่นนี้ จะเรียกว่า การฝึกแบบออนไลน์ (online training). \[\begin{aligned} \boldsymbol{\Theta}^{(i)} &= \boldsymbol{\Theta}^{(i-1)} - \frac{\alpha}{N} \cdot \nabla_{\Theta} E_n \left(\boldsymbol{\Theta}^{(i-1)}\right) \label{eq: gd online}.\end{aligned}\] การฝึกแบบออนไลน์ จะสามารถรับข้อมูลเข้ามาฝึกเพิ่มได้ตลอด บางครั้งจึงอาจถูกเรียกว่า การฝึกในโหมดเพิ่ม (training in an incremental mode).
โดยทั่วไป การฝึกแบบหมู่จะทำได้เร็วกว่า แต่ก็ต้องการหน่วยความจำมากกว่าการฝึกแบบออนไลน์. สำหรับคุณภาพการฝึก เฮย์กิน ได้อภิปรายถึงข้อดีข้อเสียว่า การฝึกแบบหมู่ จะให้การประมาณค่าเกรเดียนต์ที่แม่นยำกว่า ดังนั้น เมื่อทำงานกับวิธีลงเกรเดียนต์ แล้วจะได้ค่าพารามิเตอร์ที่ดีกว่า. นอกจากนั้น การฝึกแบบหมู่ มีธรรมชาติเข้ากับการคำนวณแบบขนานมากกว่า และสามารถนำการประมวลผลแบบขนาน (parallel processing) มาช่วยการประมวลผลได้ง่ายกว่า. เมื่อมองจากมุมมองทางสถิติศาสตร์ การฝึกแบบหมู่ เป็นรูปแบบการอนุมานทางสถิติ (statistical inference) อย่างหนึ่ง ดังนั้นการฝึกแบบหมู่ จะเหมาะกับงานการหาค่าถดถอย. แต่ข้อเสียของการฝึกแบบหมู่ ก็คือความต้องการใช้หน่วยความจำปริมาณมาก (เพราะว่าใช้ข้อมูลทั้งหมดทีเดียว ในการคำนวณแต่ละสมัย).
ข้อดีของการฝึกแบบออนไลน์ เมื่อทำร่วมกับการสลับลำดับข้อมูลในแต่ละสมัย จะช่วยลดความเสี่ยงในการเข้าไปติดอยู่ที่ค่าทำให้น้อยที่สุดท้องถิ่นได้ และเมื่อเทียบกับการฝึกแบบหมู่ การฝึกแบบออนไลน์ ต้องการใช้หน่วยความจำปริมาณน้อยกว่า. นอกจากนั้นในทางปฎิบัติแล้วพบว่า การฝึกแบบออนไลน์ สามารถใช้ประโยชน์จากข้อมูลที่ซ้ำซ้อนกันได้มากกว่าการฝึกแบบหมู่. การฝึกแบบออนไลน์ยังอาจช่วยให้การติดตามการเปลี่ยนแปลงเล็ก ๆ ในข้อมูล ทำได้สะดวกขึ้น โดยเฉพาะอย่างยิ่ง สำหรับข้อมูลที่มีลักษณะไม่นิ่งทางสถิติ (nonstationary). แม้ว่าการฝึกแบบออนไลน์ จะทำงานได้ช้ากว่า แต่การฝึกแบบออนไลน์ ก็มีการใช้อย่างแพร่หลาย โดยเฉพาะกับงานการจำแนกรูปแบบ ส่วนหนึ่ง เพราะว่า การฝึกแบบออนไลน์ สามารถขยายขึ้นไปทำงานกับข้อมูลขนาดใหญได้ง่ายกว่า. อย่างไรก็ตาม พัฒนาการต่อมา นิยมใช้การผสมการฝึกแบบหมู่ และการฝึกแบบออนไลน์ ที่เรียกว่า การฝึกแบบหมู่เล็ก ดังที่จะอภิปรายในบท [chapter: Deep Learning].
3.3.2.0.1 การกำหนดค่าเริ่มต้นในการฝึก.
ขั้นตอนวิธีในการฝึกโครงข่ายประสาทเทียม ใช้การปรับปรุงค่าพารามิเตอร์ให้ดีขึ้นเรื่อย ๆ ในแต่ละสมัยฝึก. สมัยฝึกแรกสุด ต้องการค่าเริ่มต้นของพารามิเตอร์. การกำหนดค่าเริ่มต้นของพารามิเตอร์ ที่มักเรียกว่า การกำหนดค่าน้ำหนักเริ่มต้น (weight initialization) วิธีที่นิยมในการกำหนดค่าเริ่มต้น คือการกำหนดค่าเริ่มต้นด้วยการสุ่ม (แบบฝึกหัด [ex: ann weight init]). นอกจากนั้น มีเทคนิคจำนวนมาก สำหรับวิธีการกำหนดค่าเริ่มต้นที่มีประสิทธิภาพ เช่น วิธีเหงี่ยนวิดโดรว์ (Nguyen-Widrow weight initialization) หัวข้อ [sec: weight init] อภิปรายวิธีการกำหนดค่าเริ่มต้นที่มีประสิทธิภาพ โดยเฉพาะสำหรับโครงข่ายประสาทเทียมแบบลึก.
3.3.3 โครงข่ายประสาทเทียมสำหรับการจำแนกกลุ่ม
สมการ \(\eqref{eq: ann En}\) แสดงค่าผิดพลาดกำลังสอง ซึ่งนิยมใช้เป็นฟังก์ชันจุดประสงค์ สำหรับงานการหาค่าถดถอย. การรู้จำรูปแบบ ที่บ่อยครั้ง มักจะถูกตีกรอบปัญหาเป็นการจำแนกกลุ่ม มีสองภาระกิจหลัก ๆ คือ การจำแนกค่าทวิภาค และการจำแนกกลุ่ม .
3.3.3.0.1 การจำแนกค่าทวิภาค.
การจำแนกค่าทวิภาค เป็นภาระกิจที่ต้องการทำนายผลลัพธ์ ซึ่งมีรูปแบบที่เป็นไปได้สองแบบ. รูปแบบที่เป็นไปได้ทั้งสอง นั้นมักจะถูกเลือกให้แทนด้วย \(1\) และ \(0\) เช่น ปัญหาการทายผลการตรวจข้อมูลเอ็กซ์เต้านมของมวลเนื้อ (แบบฝึกหัด [ex: mammography]) ที่ผลทายมีอยู่สองอย่างคือ เนื้อร้าย หรือ ไม่ใช่เนื้อร้าย.
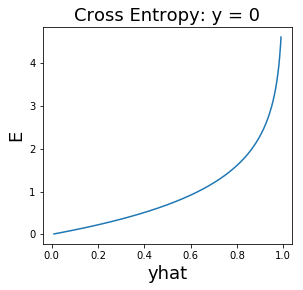
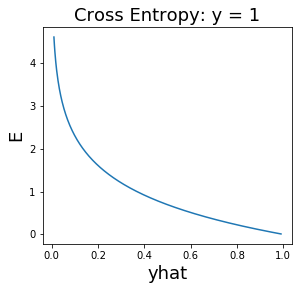
การจำแนกค่าทวิภาค (binary classification) ซึ่งต้องการเอาต์พุต \(y \in \{0, 1\}\) นิยมใช้ฟังก์ชันกระตุ้นเอาต์พุตเป็นฟังก์ชันซิกมอยด์. นั่นคือ \(h(a) = 1/(1 + e^{-a})\) ซึ่งจะทำให้ค่าที่ทำนาย \(\hat{y} \in (0,1)\). เพื่อให้การฝึกแบบจำลองทำได้มีประสิทธิภาพ ฟังก์ชันจุดประสงค์ สำหรับการจำแนกค่าทวิภาค นิยมใช้ ฟังก์ชันสูญเสียครอสเอนโทรปี (cross entropy loss). ฟังก์ชันสูญเสียครอสเอนโทรปี สำหรับการจำแนกค่าวิภาค นิยามดังสมการ \(\eqref{eq: cross entropy loss binary}\). \[\begin{aligned} E_n & = \left\{ \begin{array}{l l} -\log\left(\hat{y}(\boldsymbol{x}_n, \boldsymbol{\Theta})\right) & \quad \mbox{เมื่อ} \quad y(n) = 1,\\ -\log\left(1 - \hat{y}(\boldsymbol{x}_n, \boldsymbol{\Theta})\right) & \quad \mbox{เมื่อ} \quad y(n) = 0. \end{array} \right. \label{eq: cross entropy loss binary}\end{aligned}\] เมื่อ \(y(n)\) คือเฉลย หรือค่าตัวแปรตามของจุดข้อมูลที่ \(n^{th}\) และ \(\hat{y}(\boldsymbol{x}_n, \boldsymbol{\Theta})\) คือผลทาย สำหรับจุดข้อมูลที่ \(n^{th}\) (ที่มีตัวแปรต้นเป็น \(\boldsymbol{x}_n\)) และใช้ค่าพารามิเตอร์ \(\boldsymbol{\Theta}\). สมการ \(\eqref{eq: cross entropy loss binary}\) มักถูกเขียนย่อเป็น \[\begin{aligned} E_n &= - y_n \cdot \log(\hat{y}_n) - (1 - y_n) \cdot \log(1 - \hat{y}_n) \label{eq: cross entropy loss binary short}. \end{aligned}\] รูป 1.24 แสดงพฤติกรรมของฟังก์ชันสูญเสียชนิดค่าผิดพลาดกำลังสอง เปรียบเทียบกับชนิดครอสเอนโทรปี.
|
3.3.3.0.2 การจำแนกกลุ่ม.
การจำแนกลุ่ม เป็นภาระกิจที่ต้องการทำนายกลุ่มของรูปแบบ ตัวอย่างเช่น การรู้จำตัวเลขลายมือ (แบบฝึกหัด [ex: mnist]) ที่ต้องการระบุกลุ่มของภาพตัวเลขที่เขียนด้วยลายมือ ว่าอยู่กลุ่มตัวเลขใด ระหว่าง \(0\) ถึง \(9\).
การจำแนกกลุ่ม (classification หรือ multi-class classification) ซึ่งต้องการเอาต์พุตที่ระบุฉลากของกลุ่ม ซึ่งฉลาก นิยมกำหนดด้วยรหัสหนึ่งร้อน (one-hot coding หรือ one-of-K coding). รหัสหนึ่งร้อน จะใช้ตัวเลข \(K\) ตัว ในการระบุกลุ่ม \(K\) กลุ่ม. ตำแหน่งของเลขแต่ละตัว แทนกลุ่มที่สนใจ แต่ละกลุ่ม. หากจุดข้อมูล อยู่ในกลุ่มใด ตัวเลขที่อยู่ตำแหน่งของกลุ่มนั้นจะเป็นหนึ่ง และตัวเลขอื่น ๆ จะเป็นศูนย์. นั่นคือ เอาต์พุตในรหัสหนึ่งร้อน \(\boldsymbol{y} = [y_1, \; \ldots, \; y_K]^T\) โดย \(y_k \in \{0,1\}\) และ \(\sum_k y_k = 1\). การจำแนกกลุ่ม นิยมใช้ฟังก์ชันกระตุ้นเอาต์พุต เป็นฟังก์ชันซอฟต์แมกซ์ (softmax function) ซึ่งคำนวณโดย สมการ \(\eqref{eq: softmax vec}\). \[\begin{aligned} h(\boldsymbol{a}) = \begin{bmatrix} \frac{e^{a_1}}{\sum_{k=1}^K e^{a_k}} & \cdots & \frac{e^{a_K}}{\sum_{k=1}^K e^{a_k}} \end{bmatrix}^T \label{eq: softmax vec}\end{aligned}\] สมการ \(\eqref{eq: softmax vec}\) มักเขียนย่อเป็น \[\begin{aligned} h(a_i) = \frac{e^{a_i}}{\sum_{k=1}^K e^{a_k}} \label{eq: softmax}.\end{aligned}\] ฟังก์ชันซอฟต์แมกซ์ ช่วยให้ค่าที่ทำนาย \(\hat{\boldsymbol{y}} = h(\boldsymbol{a})\) สามารถเปรียบเทียบได้กับเฉลยที่อยู่ในรหัสหนึ่งร้อน. นั่นคือ \(\boldsymbol{\hat{y}} = [\hat{y}_1, \; \ldots, \; \hat{y}_K]^T\) โดย \(\sum_k \hat{y}_k = 1\) และ \(\hat{y}_k \in (0,1)\) สำหรับทุก \(k =1, \ldots, K\).
ในการฝึกแบบจำลอง ฟังก์ชันจุดประสงค์สำหรับการจำแนกกลุ่ม นิยมใช้ฟังก์ชันสูญเสียครอสเอนโทรปี ที่นิยามดังสมการ \(\eqref{eq: cross entropy loss category}\). \[\begin{aligned} E_n & = -\log\left(\hat{y}_c(\boldsymbol{x}_n, \boldsymbol{\Theta})\right) \label{eq: cross entropy loss category}\end{aligned}\] เมื่อ \(c\) คือดัชนีของกลุ่มที่เฉลย นั่นคือ \(y_c(n) = 1\). สมการ \(\eqref{eq: cross entropy loss category}\) มักถูกเขียนเป็น \[\begin{aligned} E_n & = -\sum_{k=1}^K y_k(n) \cdot \log \left(\hat{y}_k(\boldsymbol{x}_n, \boldsymbol{\Theta}) \right) \label{eq: cross entropy loss category short}\end{aligned}\] เมื่อ \(K\) คือจำนวนของกลุ่มทั้งหมด.
ฟังก์ชันสูญเสียครอสเอนโทรปีในสมการ \(\eqref{eq: cross entropy loss binary}\) และ \(\eqref{eq: cross entropy loss category}\) ต่างมาจากพื้นฐานเดียวกัน แต่ปรากฎรูปต่างกัน. เพื่อลดความสับสน สมการ \(\eqref{eq: cross entropy loss binary}\) จะเรียกว่า ฟังก์ชันสูญเสียครอสเอนโทรปีสำหรับการจำแนกค่าทวิภาค และอาจเรียกย่อเป็น ครอสเอนโทรปีทวิภาค (binary cross entropy). สมการ \(\eqref{eq: cross entropy loss category}\) เป็นครอสเอนโทรปีสำหรับการจำแนกกลุ่ม และอาจเรียกย่อเป็น ครอสเอนโทรปีพหุกลุ่ม (multi-class cross entropy หรือ categorical cross entropy).
3.4 การประยุกต์ใช้โครงข่ายประสาทเทียม
หัวข้อ 1.3 อภิปรายกลไกที่จำเป็นสำหรับการทำงานของโครงข่ายประสาทเทียม. การประยุกต์ใช้โครงข่ายประสาทเทียม ในทางปฏิบัติ มีประเด็นอื่น ๆ ที่ต้องพิจารณาประกอบ เพื่อให้การฝึก และการใช้งานโครงข่ายประสาทเทียมทำงานได้ดี. ประเด็นหนึ่งที่สำคัญ และค่อนข้างจะทั่วไป ไม่ได้เจาะจงกับภาระกิจใดเฉพาะ คือ การทำนอร์มอไลซ์ (normalization) สำหรับอินพุต. การทำนอร์มอไลซ์สำหรับอินพุต คือ การปรับขนาดอินพุต เพื่อช่วยให้การฝึก และการทำงานของโครงข่ายประสาทเทียมทำได้ง่ายขึ้น.
ก่อนอภิปรายวิธีการทำนอร์มอไลซ์อินพุต พิจารณาผลการฝึก และทดสอบโครงข่ายประสาทเทียมของข้อมูลสองชุด ซึ่งลักษณะข้อมูล ความก้าวหน้าในการฝึก และผลการทำนายกับข้อมูลทดสอบ แสดงในรูป 1.30. ผลการทดสอบ (ระบุในคำบรรยายภาพ) และภาพในรูป 1.30 แสดงให้เห็นชัดเจนว่า แบบจำลองทำงานได้ดีกับข้อมูลชุดเอ (dataset A) แต่ทำงานได้แย่มากกับข้อมูลชุดบี (dataset B). ข้อมูลทั้งสองชุด มีลักษณะความสัมพันธ์ระหว่างตัวแปรต้น \(x\) และตัวแปรตาม \(y\) ในแบบเดียวกัน. ความต่างระหว่างข้อมูลชุดเอและชุดบี มีอย่างเดียวคือ ขนาดของอินพุตของข้อมูล. ขนาดของอินพุตของข้อมูลชุดเอ อยู่ในช่วง \(0\) ถึง \(1\) ในขณะที่ขนาดของอินพุตของข้อมูลชุดบี อยู่ในช่วง \(100\) ถึง \(110\).
 |
 |
 |
 |
 |
 |
พิจารณากลไกของการแพร่กระจายย้อนกลับ โดยเฉพาะสมการ \(\eqref{eq: backprop delta q < L}\) จะเห็นว่า \(h'(a_j^{(q)})\) มีผลโดยตรงกับเกรเดียนต์. ค่า \(h'(a_j^{(q)})\) คืออนุพันธ์ของฟังก์ชันกระตุ้น ซึ่งซิกมอยด์เป็นฟังก์ชันกระตุ้นที่ใช้. อนุพันธ์ของซิกมอยด์ (แสดงในรูป 1.31) จะมีค่าน้อยมาก ๆ เมื่อตัวกระตุ้นมีค่าใหญ่ ๆ (เช่นมากกว่าห้า หรือน้อยกว่าลบห้า) ซึ่งจะขับค่าของฟังก์ชันซิกมอยด์ไปที่ปลาย 2 (ค่าใกล้ ๆ หนึ่ง หรือค่าใกล้ ๆ ศูนย์). ค่าอินพุตที่มีขนาดใหญ่ จะทำให้ตัวกระตุ้นมีค่าใหญ่ และจะส่งผลให้อนุพันธ์ของซิกมอยด์มีค่าน้อย ซึ่งส่งผลต่อให้เกรเดียนต์มีค่าน้อย และสุดท้าย ส่งผลให้การฝึกแบบจำลองทำได้ช้า.
การทำนอร์มอไลซ์อินพุต ซึ่งเป็นการปรับขนาดของอินพุตให้อยู่ในช่วงที่การฝึกแบบจำลองทำได้ง่าย จึงสำคัญอย่างมากในทางปฏิบัติ. การเรียนรู้สำหรับสิ่งมีชีวิตก็เช่นเดียวกัน หากสภาพแวดล้อมเหมาะกับการเรียนรู้ สิ่งมีชีวิตก็จะเรียนรู้ได้เร็วขึ้น เรียนรู้ได้ดีขึ้น.
การทำนอร์มอไลซ์สามารถทำได้หลายวิธี สองวิธีทั่ว ๆ ไปที่นิยมมาก คือ วิธีการปรับสู่ช่วงที่กำหนด และวิธีการปรับสู่ค่าสถิติที่กำหนด. วิธีการปรับสู่ช่วงที่กำหนด จะปรับขนาดของอินพุต ให้ค่าอยู่ในช่วงที่กำหนด เช่น \([-1,1]\) หรือ \([0,1]\). หากช่วงที่ต้องการคือ \([x'_{\min}, x'_{\max}]\) ค่าอินพุตที่ผ่านการทำนอร์มอไลซ์ หรือเรียกสั้น ๆ ว่า นอร์มอไลด์อินพุต (normalized input) สัญลักษณ์ \(x'\) สามารถคำนวณจาก \[\begin{aligned} x' = (x'_{\max} - x'_{\min}) \cdot \frac{x - x_{\min}}{x_{\max} - x_{\min}} + x'_{\min} \label{eq: ann normalization [0,1]}\end{aligned}\] เมื่อ \(x\) คือค่าอินพุตเดิม และ \(x_{\min}\) กับ \(x_{\max}\) คือค่าน้อยที่สุดกับค่ามากที่สุดของอินพุตเดิม.
วิธีการปรับสู่ค่าสถิติที่กำหนด นิยมปรับค่าอินพุต เพื่อให้ค่าเฉลี่ย และค่าเบี่ยงเบนมาตราฐาน เป็น \(0\) กับ \(1\) ตามลำดับ. ดังนั้น นอร์มอไลด์อินพุต \(x'\) สามารถคำนวณได้จาก \[\begin{aligned} x' = \frac{x - \bar{x}}{\sigma_x} \label{eq: ann normalization stat}\end{aligned}\] เมื่อ \(\bar{x}\) และ \(\sigma_x\) คือค่าเฉลี่ยและค่าเบี่ยงเบนมาตราฐาน ของค่าอินพุตเดิม.
หมายเหตุ สำหรับอินพุตขนาดหลายมิติ \(\boldsymbol{x} \in \mathbb{R}^D\) เมื่อ \(D\) เป็นจำนวนมิติของปริภูมิอินพุต. การทำนอร์มอไลซ์ ยังช่วยรักษาสมดุลของขนาดของอินพุตในมิติต่าง ๆ กันด้วย. การทำนอร์มอไลซ์ จะทำแต่ละมิติ เช่น กรณีสองมิติ \(\boldsymbol{x} = [x_1, x_2]^T\) และต้องการทำนอร์มอไลซ์ ให้อยู่ในช่วง \([0,1]\) ทั้งคู่ จะดำเนินการโดย \[\boldsymbol{x}' = \begin{bmatrix} x'_1 \\ x'_2 \end{bmatrix} = \begin{bmatrix} (x_1 - {x_1}_{\min})/({x_1}_{\max} - {x_1}_{\min}) \\ (x_2 - {x_2}_{\min})/({x_2}_{\max} - {x_2}_{\min}) \\ \end{bmatrix}\] เมื่อ \(x'_1\) และ \(x'_2\) คือค่านอร์มอไลด์อินพุต ของมิติที่หนึ่งและมิติที่สองตามลำดับ และ \({x_1}_{\min}\) กับ \({x_1}_{\max}\) คือค่าน้อยที่สุดกับค่ามากที่สุดของอินพุตเดิมในมิติที่หนึ่งและ \({x_2}_{\min}\) กับ \({x_2}_{\max}\) คือค่าน้อยที่สุดกับค่ามากที่สุดของอินพุตเดิมในมิติที่สอง.
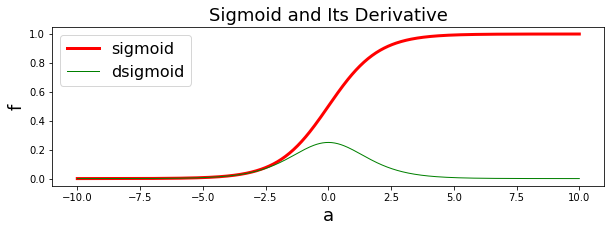
3.4.0.0.1 การหยุดก่อนกำหนด.
ประเด็นของการโอเวอร์ฟิต และคุณสมบัติความทั่วไป เป็นประเด็นสำคัญสำหรับการใช้งานแบบจำลองทำนาย ที่รวมถึงโครงข่ายประสาทเทียม. การเลือกใช้แบบจำลองที่มีความยืดหยุ่นสูง ๆ เช่น การใช้โครงข่ายประสาทเทียมสองชั้น ที่มีจำนวนหน่วยซ่อนมาก ๆ หรือการใช้โครงข่ายประสาทเทียมที่มีชั้นลึก ๆ ก็เสี่ยงที่จะเกิดการโอเวอร์ฟิตได้.
รูป 1.37 แสดงผลการฝึกโครงข่ายสองชั้นขนาด \(100\) หน่วยซ่อน กับข้อมูลฝึก \(40\) จุดข้อมูล. ราว ๆ \(5000\) ถึง \(10000\) สมัย ให้ผลการทำนายที่ดี และการฝึกต่อเพิ่มไป นอกจากเสียเวลาเพิ่ม แล้วยังทำให้แบบจำลองโอเวอร์ฟิตอีกด้วย ดังเห็นได้จากค่าผิดพลาดกับข้อมูลทดสอบที่เพิ่มขึ้น (ภาพล่างสุดซ้าย) และเวลาที่ใช้ยังเป็นราว ๆ \(9\) ถึง \(18\) เท่าอีกด้วย เวลาที่ใช้ฝึกระบุในคำบรรยายภาพ. หมายเหตุ เวลาที่ระบุ แสดงเป็นเวลานอร์มอไลซด์ (normalized time). นั่นคือ เวลาที่แสดงเป็นอัตราส่วน โดยใช้เวลาที่อ้างอิงเป็นตัวหาร. เวลาที่รายงานในรูป 1.37 ใช้เวลาที่ฝึกแบบจำลอง \(5000\) สมัยเป็นเวลาอ้างอิง. การรายงานเวลา ด้วยเวลานอร์มอไลซด์ แทนเวลาสมบูรณ์ ช่วยบอกภาพรวมของเวลาการทำงาน โดยลดความจำเป็นในการรายงานรายละเอียด ของฮาร์แวร์และระบบที่ใช้ทดสอบลง.
การฝึกโครงข่ายประสาทเทียมใช้เวลานาน การฝึกโดยการใช้สมัยฝึกมาก จนเกิดโอเวอร์ฟิต นอกจากจะได้แบบจำลองที่ไม่มีคุณสมบัติความทั่วไปแล้ว ยังเสียเวลาฝึกด้วย. การปฏิบัติที่นิยม ก็คือ การหยุดก่อนกำหนด (early stopping). การหยุดก่อนกำหนด คือ การใช้เงื่อนไขเพื่อหยุดการฝึก โดยเงื่อนไข คือเมื่อค่าผิดพลาดของข้อมูลทดสอบสูงขึ้นกว่าเดิม ให้หยุดการฝึก. ค่าผิดพลาดของข้อมูลทดสอบสูงขึ้นกว่าเดิม เป็นสัญญาณของการโอเวอร์ฟิต และเพื่อให้ไม่มีการใช้ข้อมูลทดสอบสุดท้าย ในกระบวนการฝึกจริง ๆ ข้อมูลทดสอบ เพื่อใช้สำหรับการหยุดก่อนกำหนดจะแบ่งออกมาจากข้อมูลชุดฝึก เรียกว่า ข้อมูลตรวจสอบ (validation data). ข้อมูลตรวจสอบ เป็นข้อมูลอีกชุดที่แยกออกมา. ข้อมูลตรวจสอบ ไม่ใช้ในการฝึก (ไม่ใช้ในการคำนวณเพื่อปรับค่าน้ำหนัก) และไม่ใช้ในการทดสอบสุดท้าย (ไม่ใช้ในการทดสอบ เพื่อรายงานผลการทำงานของแบบจำลอง). ข้อมูลตรวจสอบ เป็นข้อมูลที่ใช้ในกระบวนการฝึก แต่ไม่ได้ใช้ในการฝึก ข้อมูลตรวจสอบ จะใช้เพื่อเลือกแบบจำลอง หรือใช้เพื่อเลือกความซับซ้อนของแบบจำลอง (เช่น จำนวนหน่วยซ่อน) หรือใช้เพื่อการหยุดก่อนกำหนด เป็นต้น.
 |
 |
 |
 |
 |
 |
3.5 คำแนะนำสำหรับการใช้แบบจำลองทำนาย
การประเมินผล เป็นกลไกที่สำคัญมากสำหรับการใช้แบบจำลองทำนาย. แต่หากผลที่ประเมินได้ไม่น่าพอใจ และต้องการปรับปรุงให้ได้ผลการทำนายดีขึ้น มีทางเลือกต่าง ๆ มากมาย เช่น การเพิ่มจำนวนข้อมูลที่จะใช้สำหรับการฝึก หรือการคัดเลือกตัวแปรต้นของข้อมูล โดยเลือกเฉพาะคุณลักษณะที่สำคัญ นั่นคือเลือกเฉพาะมิติ บางมิติที่สำคัญ มาใช้เป็นอินพุตสำหรับแบบจำลอง หรือการเพิ่มคุณลักษณะใหม่เข้าไปในอินพุตของแบบจำลอง หรือการเพิ่มความซับซ้อนของแบบจำลองขึ้น หรือการลดความซับซ้อนของแบบจำลองลง.
ทางเลือกที่หลากหลาย อาจทำให้สับสนได้ และการปรับปรุงแบบจำลอง ควรจะลองทำอะไรก่อน อะไรหลัง ซึ่งการลองทำแต่ละอย่าง อาจใช้เวลามาก และยังอาจเพิ่มงบประมาณด้วย เช่น การออกไปหาข้อมูลมาเพิ่ม (เพิ่มจำนวนจุดข้อมูล) หรือการเพิ่มลักษณะสำคัญชนิดใหม่เข้าไป (เพิ่มมิติใหม่สำหรับอินพุต). ผู้เชี่ยวชาญศาสตร์การเรียนรู้ของเครื่อง แอนดรูว์ อึ้ง แนะนำว่า ก่อนตัดสินใจเลือกทดลองปรับปรุงด้วยวิธีใด ควรทำการทดลองง่าย ๆ และใช้เส้นโค้งเรียนรู้ (Learning Curve) เป็นตัวชี้แนะ. การใช้เส้นโค้งเรียนรู้ มีพื้นฐานมาจากการศึกษาเรื่องคุณภาพการทำนาย ที่สัมพันธ์กับความลำเอียง (bias 3) และความแปรปรวน (variance).
3.5.1 ความลำเอียงกับความแปรปรวน
พิจารณารูป 1.5 ที่ใช้ฟังก์ชันพหุนามทำนายข้อมูล. ภาพ ข ใน รูป 1.8 แสดงค่าผิดพลาดที่ได้ต่อระดับขั้น. ระดับขั้น บอกความซับซ้อนของแบบจำลองฟังก์ชันพหุนาม. ที่ความซับซ้อนของแบบจำลองที่เหมาะสม ค่าผิดพลาดของชุดข้อมูลทดสอบ จะมีค่าต่ำที่สุด.
ฟังก์ชันพหุนามระดับขั้นเก้าก็โอเวอร์ฟิตข้อมูลอย่างชัดเจน. ส่วนฟังก์ชันพหุนามระดับขั้นศูนย์ ระดับขั้นหนึ่ง และระดับขั้นสองอันเดอร์ฟิตของข้อมูลอย่างชัดเจน. การอันเดอร์ฟิต (underfit) หมายถึง การที่ความซับซ้อนของแบบจำลอง ไม่เพียงพอที่จะประมาณความสัมพันธ์ของข้อมูลได้. ช่วงที่ความซับซ้อนของแบบจำลองน้อยเกินไป มีจุดสังเกตสำคัญคือ ค่าผิดพลาดจะสูงกับทั้งข้อมูลชุดทดสอบและชุดฝึกหัด. เมื่อความซับซ้อนของแบบจำลองไม่พอ แบบจำลองจะไม่ยืดหยุ่นพอที่ปรับตัว เพื่อลดค่าผิดพลาดกับข้อมูลชุดฝึกลงได้. กรณีที่แบบจำลองทำงานได้ไม่ดี เนื่องจากความซับซ้อนของแบบจำลองน้อยเกินไปนี้ จะเรียกว่า กรณีที่มีความลำเอียงสูง (high bias) ซึ่งสื่อถึงการอันเดอร์ฟิต.
ส่วนกรณีที่ความซับซ้อนของแบบจำลองมากเกินไป ซึ่งคือกรณีการโอเวอร์ฟิตมีจุดสังเกตที่สำคัญคือ ค่าผิดพลาดกับชุดฝึกจะต่ำมาก แต่ค่าผิดพลาดกับชุดทดสอบจะสูง. แบบจำลองที่มีความซับซ้อนมาก จะสามารถปรับพฤติกรรมการทำนาย เพื่อลดค่าผิดพลาดกับข้อมูลชุดฝึกหัดลงได้ดี แต่หากความซับซ้อนมากเกินไป จนไปลดค่าผิดพลาดกับข้อมูลชุดฝึกหัดที่เกิดจากสัญญาณรบกวนด้วย แบบจำลองจะทำนายข้อมูลชุดทดสอบได้ไม่ดี. กรณีนี้จะเรียกว่า เป็นกรณีที่มีความแปรปรวนสูง (high variance) ซึ่งสื่อถึงการโอเวอร์ฟิต.
กล่าวอีกอย่างหนึ่ง ความลำเอียงสูง หมายถึงแบบจำลองของไม่ยืดหยุ่นมากพอ ส่วนความแปรปรวนสูงหมายถึงแบบจำลองของยืดหยุ่นมากเกินไป. แบบจำลองที่ดีที่สุดที่ทำได้ คือ แบบจำลองที่ลดให้ทั้งความลำเอียงและความแปรปรวนมีค่าต่ำ. แต่ไม่ว่าแบบจำลองไหนก็ตาม เราทำดีที่สุด ได้แค่ดีที่สุด จะฝืนข้อจำกัดของธรรมชาติไม่ได้.
ทฤษฎีที่กล่าวถึงข้อจำกัดของการทำแบบจำลองนี้คือ ทวิบถของความลำเอียงกับความแปรปรวน (ฺBias/Variance Dilemma). ทวิบถของความลำเอียงกับความแปรปรวน เสนอโดย เจมันและคณะ จากการศึกษาความสามารถ และขีดจำกัดของการทำแบบจำลอง. ทวิบถของความลำเอียงกับความแปรปรวน สรุปว่า เราสามารถทำแบบจำลองให้ดีที่สุดได้ โดยลดทั้งค่าความลำเอียงและความแปรปรวนให้ต่ำ. แต่ค่าผิดพลาดก็มีขีดจำกัดหนึ่ง (ขึ้นกับธรรมชาติของปัญหา) ที่เราไม่สามารถลดค่าผิดพลาดลงไปให้ต่ำกว่านั้นได้. การที่เราพยายามจะลดค่าผิดพลาดให้ต่ำกว่านั้น โดยการลดส่วนหนึ่ง ก็จะไปเพิ่มอีกส่วน เช่น หากพยายามลดค่าผิดพลาดจากความลำเอียงมากเกินไป ก็จะทำให้ส่วนที่เกิดจากความแปรปรวนเพิ่ม และในทางกลับกัน หากพยายามลดค่าผิดพลาดจากความแปรปรวนมากเกินไป ก็จะทำให้ส่วนที่เกิดจากความลำเอียงเพิ่ม.
3.5.2 เส้นโค้งเรียนรู้
เส้นโค้งเรียนรู้ (Learning Curve) เป็นเครื่องมือช่วยแสดงความสัมพันธ์ระหว่างความพยายามที่ใช้ไปในการฝึกแบบจำลอง กับผลการทำงานของแบบจำลอง. เส้นโค้งเรียนรู้ สามารถใช้เพื่อช่วยให้เงื่อนงำว่า แบบจำลองที่ใช้อยู่ มีความเสี่ยงที่จะมีความลำเอียงสูง หรือเสี่ยงที่จะมีความแปรปรวนสูง. เส้นโค้งเรียนรู้ สร้างโดย การตรวจสอบผลการฝึกแบบจำลองที่จำนวนจุดข้อมูลฝึกต่าง ๆ แล้วนำค่าผิดพลาดเฉลี่ยกับชุดฝึก และค่าผิดพลาดเฉลี่ยกับชุดทดสอบ มาวาดกราฟ ดังแสดงในรูป 1.39.
การวัดค่าผิดพลาดกับชุดฝึก วัดเฉพาะกับจุดข้อมูลที่ใช้ฝึก เช่น หากฝึกแบบจำลองด้วย \(10\) จุดข้อมูล ก็หาค่าผิดพลาดของการทำนายค่า \(10\) จุดข้อมูลนี้. ดังนั้น เมื่อจำนวนจุดข้อมูลฝึกน้อย แบบจำลองมีโจทย์ที่ต้องทำน้อย ก็มีโอกาสที่จะทำค่าผิดพลาดของชุดฝึกน้อยด้วย. เมื่อเพิ่มจำนวนจุดข้อมูลฝึกขึ้น ค่าผิดพลาดของชุดฝึกก็จะเพิ่มขึ้น และลู่เข้าสู่ค่า ๆ หนึ่ง. ในขณะเดียวกัน เมื่อจำนวนจุดข้อมูลฝึกเพิ่มขึ้น ค่าผิดพลาดของชุดทดสอบจะลดลงจนลู่เข้าสู่ค่า ๆ หนึ่ง.
ในกรณีที่ แบบจำลองมีความเสี่ยงจากความลำเอียงสูง ถ้าข้อมูลทดสอบ และข้อมูลฝึกมีปริมาณเพียงพอ พฤติกรรมการทำนายของแบบจำลอง จะให้ผลในลักษณะเดียวกัน และทำให้ค่าผิดพลาดจากชุดฝึก และจากชุดทดสอบ มีค่าใกล้เคียงกัน. แต่กรณีที่แบบจำลองมีความแปรปรวนสูง นั่นคือ แบบจำลองมีความยืดหยุ่นมากเกินไป มากจนพอที่จะปรับตัวเข้ากับสัญญาณรบกวนในข้อมูลฝึกได้. ผลคือแบบจำลองสามารถลดค่าผิดพลาดของชุดฝึกได้ต่ำ และทำให้ผลต่างระหว่างค่าผิดพลาดจากชุดฝึก และจากชุดทดสอบมีค่าต่างกัน. ดังนั้นความต่างระหว่างค่าผิดพลาดจากข้อมูลทดสอบและจากข้อมูลฝึกจึงสามารถใช้บ่งชี้สถานการณ์คร่าว ๆ ของแบบจำลองได้.
 |
 |
รูป 1.39 เป็นภาพวาดเพื่อให้เห็นภาพรวม แต่ ในสถานการณ์จริง เส้นโค้งเรียนรู้ที่ได้ อาจจะมีสัญญาณรบกวนมาก หรือแม้แต่สเกลของการวาดกราฟ อาจทำให้ต้องใช้ความระมัดระวัง ในการอ่านผลจากเส้นโค้งเรียนรู้. รูป 1.44 แสดงกระบวนการทดสอบแบบจำลอง เพื่อวาดเส้นโค้งเรียนรู้. รูป 1.50 แสดงเส้นโค้งเรียนรู้ที่ได้จาก แบบจำลองที่มีความซับซ้อนต่าง ๆ กัน เพื่อให้เห็นตัวอย่างลักษณะของเส้นโค้งเรียนรู้ ในกรณีต่าง ๆ.
จากรูป 1.44 และคำบรรยาย แบบจำลองโครงข่ายประสาทเทียมสองชั้น ขนาด \(4\) หน่วยซ่อน อันเดอร์ฟิตข้อมูล และเส้นโค้งเรียนรู้ ก็ลู่เข้าหากัน โดยอัตราความต่างระหว่างค่าผิดพลาดจากชุดทดสอบและชุดฝึกค่อนข้างต่ำ (ประมาณ \(1.55\)). แบบจำลองโครงข่ายประสาทเทียมสองชั้นขนาด \(200\) หน่วยซ่อน โอเวอร์ฟิตข้อมูลอย่างชัดเจน (รูป 1.44) และเส้นโค้งเรียนรู้ก็ลู่เข้าห่างกันชัดเจน โดยอัตราความต่างระหว่างค่าผิดพลาดจากชุดทดสอบและชุดฝึกสูง (ประมาณ \(5.62\) รูป 1.50).
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
หลังจากพอรู้แล้วว่า สถานการณ์อยู่ในกรณีความลำเอียง หรืออยู่ในกรณีความแปรปรวนสูง แอนดรูว์ อึ้ง แนะนำให้พิจารณาทางเลือก ดังนี้
เก็บข้อมูลมาเพิ่มสำหรับการฝึก. การเพิ่มจำนวนข้อมูลในการฝึก จะช่วยในกรณีความแปรปรวนสูง.
เลือกเฉพาะบางมิติของข้อมูลมาเป็นอินพุต. การเลือกเฉพาะบางมิติของข้อมูลมาเป็นอินพุต. การลดมิติของอินพุตลง ก็จะช่วยในกรณีความแปรปรวนสูง โดยเฉพาะ สำหรับโครงข่ายประสาทเทียม. ตัวอย่าง เช่น โครงข่ายประสาทเทียมสองชั้น ที่มีจำนวนหน่วยซ่อนเท่าเดิม การลดมิติของอินพุตลง เท่ากับลดจำนวนพารามิเตอร์ลง.
เพิ่มลักษณะที่สำคัญใหม่เข้าไปในอินพุต. การเพิ่มลักษณะที่สำคัญใหม่เข้าไปในอินพุต การเพิ่มมิติของอินพุตขึ้น โดยทั่วไปแล้ว จะช่วยในกรณีความลำเอียงสูง.
เพิ่มความซับซ้อนของแบบจำลองขึ้น. การเพิ่มความซับซ้อนของแบบจำลอง เช่น การเพิ่มจำนวนหน่วยซ่อน จะช่วยในกรณีความลำเอียงสูง.
ลดความซับซ้อนของแบบจำลองลง. การลดความซับซ้อนของแบบจำลอง เช่น การลดจำนวนหน่วยซ่อน การทำเรกูลาไรซ์ หรือ การทำการหยุดก่อนกำหนด จะช่วยในกรณีความแปรปรวนสูง.
ตาราง 1.4 สรุปทางเลือกที่แอนดรูว์ อึ้ง แนะนำ สำหรับกรณีความลำเอียงสูง และกรณีความแปรปรวนสูง. สุดท้าย หากลองวิธีทั่ว ๆ ไปดังนี้แล้ว ผลยังไม่น่าพอใจ อาจจะลองวิเคราะห์ และตรวจสอบผลที่ขั้นตอนวิธีทำผิด ดูว่าผิดลักษณะไหน อย่างไร. เผื่อว่า อาจจะพบคุณสมบัติเฉพาะบางอย่างที่ผลมักจะผิด เช่น หากเป็นการจำแนกตัวเลขจากภาพ ขั้นตอนวิธีที่ใช้ อาจจะจำแนกเลข 2 เป็นเลข 4 บ่อย ๆ ซึ่งเมื่อดูภาพของเลขที่จำแนกผิด ก็อาจพบว่า มีรูปแบบการเขียนเลข 2 แบบหนึ่ง ที่มักจะจำแนกผิด. หากพบรูปแบบเฉพาะนั้น อาจเพิ่มการจัดการพิเศษเฉพาะสำหรับรูปแบบนั้นได้.
| กรณี | ||
| ทางเลือก | ความลำเอียงสูง | ความแปรปรวนสูง |
| เพิ่มรอบฝึก | แนะนำ | |
| เพิ่มจำนวนหน่วยย่อย | แนะนำ | |
| ทำเรกูลาไรซ์ | แนะนำ | |
| ทำหยุดก่อนกำหนด | แนะนำ | |
| ลดมิติของอินพุตลง | แนะนำ | |
| เพิ่มมิติของอินพุตขึ้น | แนะนำ | |
| เพิ่มจำนวนจุดข้อมูลฝึก | แนะนำ | |
3.6 อภิธานศัพท์
- การปรับเส้นโค้ง (curve fitting):
การปรับพฤติกรรมของแบบจำลองทำนาย โดยการเปลี่ยนค่าของพารามิเตอร์ เพื่อให้พฤติกรรมทำนายสอดคล้องกับข้อมูลที่มี.
- จุดข้อมูล (datapoint):
ตัวอย่างข้อมูลที่มีค่าของตัวแปรต้น \(x\) และตัวแปรตาม \(y\) ที่เป็นคู่กัน.
- ฟังก์ชันพหุนาม (polynomial function):
ฟังก์ชัน \(f: \mathbb{R} \mapsto \mathbb{R}\) ที่แสดงความสัมพันธ์ระหว่างตัวแปรต้น \(x\) และตัวแปรตาม \(y\) ด้วยสมการพหุนาม \(y = f(x, \boldsymbol{w}) = \sum_{m=0}^M w_m x^m\) เมื่อ พารามิเตอร์ของฟังก์ชัน \(\boldsymbol{w}\) \(= [w_0, \; w_1, \; \ldots, \; w_M]^T\).
- การฝึก (training):
การฝึก หรือการเรียนรู้ คือการปรับค่าพารามิเตอร์ของแบบจำลอง เพื่อให้แบบจำลองมีพฤติกรรมการทำนายสอดคล้องกับข้อมูล.
- ค่าเฉลย (ground truth):
ค่าของตัวแปรตาม \(y\) จากข้อมูล ที่คู่กับตัวแปรต้น \(x\) ที่สนใจ.
- คุณสมบัติความทั่วไป (generalization):
ความสามารถของแบบจำลองทำนาย ที่สามารถทำนายข้อมูลที่ไม่เคยเห็นได้ดี.
- ข้อมูลฝึก (training data):
ข้อมูลที่ใช้ในกระบวนการฝึกแบบจำลอง
- ข้อมูลทดสอบ (test data):
ข้อมูลที่ใช้ในทดสอบแบบจำลอง.
- การโอเวอร์ฟิต (overfitting):
การที่แบบจำลองสามารถทำนายข้อมูลฝึกได้ดี แต่ทำนายข้อมูลใหม่ที่ไม่เคยเห็นได้ไม่ดี นั่นคือ การที่แบบจำลองไม่มีคุณสมบัติความทั่วไป.
- ความซับซ้อนของแบบจำลอง (model complexity):
การยืดหยุ่นของแบบจำลอง อาจบ่งชี้ได้จากจำนวนพารามิเตอร์ของแบบจำลอง.
- โครงข่ายประสาทเทียม (artificial neural network):
แบบจำลองคำนวณ ที่ทำการคำนวณ โดยใช้หน่วยคำนวณย่อยหลาย ๆ หน่วย ที่แต่ละหน่วยทำการคำนวณในแบบคล้าย ๆ กัน.
- เพอร์เซปตรอนหลายชั้น (multi-layer perceptron):
โครงข่ายประสาทเทียม ที่หน่วยคำนวณต่าง ๆ ต่อกันเป็นโครงข่ายในลักษณะชั้นคำนวณ.
- โหนด หรือหน่วยคำนวณ (node หรือ unit):
การคำนวณย่อยของโครงข่ายประสาทเทียม ที่มีลักษณะการคำนวณง่าย ๆ ไม่ซับซ้อน.
- ชั้นคำนวณ (layer):
กลุ่มของโหนด ในโครงข่ายประสาทเทียม ที่จัดโครงสร้างเป็นลักษณะชั้นคำนวณ โดย กลุ่มของโหนดในชั้นคำนวณเดียวกัน จะรับอินพุตจาก(กลุ่มของโหนดใน)ชั้นคำนวณก่อนหน้า หรือจะส่งเอาต์พุตออกไปให้(กลุ่มของโหนดใน)ชั้นคำนวณถัดไป หรือทั้งสองอย่าง.
- ชั้นซ่อน (hidden layer):
ชั้นคำนวณที่จะส่งเอาต์พุตออกไปให้(กลุ่มของโหนดใน)ชั้นคำนวณถัดไป โดยเอาต์พุตของชั้นซ่อนจะไม่ใช่เอาต์พุตสุดท้ายของโครงข่าย.
- หน่วยซ่อน (hidden node หรือ hidden unit):
โหนดในชั้นซ่อน.
- ค่าน้ำหนักและค่าไบอัส (weights and biases):
ค่าพารามิเตอร์ต่าง ๆ ของโครงข่ายประสาทเทียม.
- ฟังก์ชันกระตุ้น (activation function):
ฟังก์ชันคำนวณของโหนด.
- ชั้นเอาต์พุต (output layer):
ชั้นคำนวณชั้นสุดท้าย ที่เอาต์พุตของชั้น จะเป็นเอาต์พุตของโครงข่าย.
- การแพร่กระจายย้อนกลับ (backpropagation หรือ error backpropagation):
ขั้นตอนวิธีการคำนวณหาค่าเกรเดียนต์ เพื่อปรับค่าน้ำหนัก สำหรับโครงข่ายประสาทเทียม.
- การฝึกแบบหมู่ (batch training):
การฝึกที่ใช้ข้อมูลฝึกทั้งหมดทีเดียว นั่นคือ การปรับค่าพารามิเตอร์ทำเดียวในแต่ละสมัยฝึก.
- การฝึกแบบออนไลน์ (online training):
การฝึกที่ใช้ข้อมูลฝึกทีละหนึ่งจุดข้อมูล นั่นคือ การปรับค่าพารามิเตอร์จะทำหลาย ๆ ครั้ง แต่ละครั้งสำหรับแต่ละจุดข้อมูล และจะทำจนกว่าจะครบทุกจุดข้อมูล ในแต่ละสมัยฝึก.
- สมัย (epoch):
รอบการปรับค่าพารามิเตอร์ โดยแต่ละรอบจะนับเมื่อมีการใช้ข้อมูลฝึกครบทุกจุด.
- อัตราเรียนรู้ (learning rate):
ขนาดก้าว ที่เป็นค่าสเกล่าร์ เพื่อควบคุมความเร็วในการฝึกแบบจำลอง เป็นค่าที่ใช้กับขั้นตอนวิธีการหาค่าดีที่สุดที่อยู่เบื้องหลังการฝึก.
- การกำหนดค่าน้ำหนักเริ่มต้น (weight initialization):
การกำหนดค่าน้ำหนักและไบอัส ให้กับโครงข่ายประสาทเทียม ก่อนการฝึก.
- การจำแนกค่าทวิภาค (binary classification):
ภาระกิจการทำนาย ที่ผลการทำนายมีได้สองแบบ.
- ฟังก์ชันสูญเสียครอสเอนโทรปี (cross entropy loss):
ฟังก์ชันจุดประสงค์ สำหรับการจำแนกค่าทวิภาค หรือการจำแนกกลุ่ม.
- รหัสหนึ่งร้อน (one-hot coding หรือ one-of-K coding):
รูปแบบแทนข้อมูลที่มีลักษณะเป็นกลุ่ม โดย รหัสจะมีจำนวนส่วนประกอบเท่ากับจำนวนกลุ่มทั้งหมด และตำแหน่งของแต่ละส่วนประกอบ แทนฉลากของกลุ่มแต่ละกลุ่ม. รหัสจะระบุฉลากของกลุ่ม โดยกำหนดให้ ส่วนประกอบที่อยู่ตำแหน่งฉลากนั้น มีค่าเป็นหนึ่ง และส่วนประกอบอื่น ๆ มีค่าเป็นศูนย์.
- ซอฟต์แมกซ์ (softmax):
ฟังก์ชันคำนวณ เพื่อควบคุมให้เอาต์พุต ให้อยู่ในรูปแบบที่สามารถเปรียบเทียบได้กับรหัสหนึ่งร้อน.
- การทำนอร์มอไลซ์อินพุต (input normalization):
การปรับขนาดของอินพุตทั้งหมด.
- การหยุดก่อนกำหนด (early stopping):
การทำเงื่อนไขจบการฝึก โดยใช้ข้อมูลตรวจสอบ.
- ข้อมูลตรวจสอบ (validation data):
ชุดข้อมูล เพื่อเสริมกระบวนการเตรียมแบบจำลอง อาจใช้ช่วยกระบวนการฝึก แต่ไม่ได้ใช้ฝึกแบบจำลองโดยตรง.